Innovation

Spot dessine avec Diffusion et GCode
Nous avons récemment décidé de mettre nos compétences et notre créativité à l'épreuve en organisant un hackathon de 16 heures axé sur l'IA. Cet événement a été conçu non seulement pour défier notre équipe, mais aussi pour explorer les capacités de pointe de l'IA et de la robotique. L'environnement du hackathon favorise un esprit d'innovation et de collaboration, encourageant les participants à penser en dehors des sentiers battus et à repousser les limites de ce qui est possible dans un délai limité.
Le hackathon a été rendu encore plus excitant grâce au généreux parrainage de Modal Labs, qui nous a fourni 5 000 $ en crédits de calcul sans serveur. Ce soutien nous a permis d'accéder à des GPU haut de gamme comme les H100s, cruciaux pour les tâches de calcul intensif requises pour les modèles d'IA avancés. De plus, en tant que partenaires de Boston Dynamics, nous avions à notre disposition nos deux robots Spot (Spot et Dot). Ces robots polyvalents sont capables d'effectuer une large gamme de tâches, et leurs capacités avancées de mobilité et de manipulation en faisaient les candidats parfaits pour un projet de 16 heures. Tout cela nous a offert une occasion unique de combiner une IA de pointe avec une robotique de pointe, créant ainsi un cadre idéal pour un projet innovant.
Avec mes collègues Robin Kurtz, notre responsable dédié de Spot, et Cassandre Pochet, notre spécialiste du clean code, nous nous sommes lancés dans un projet passionnant pour démontrer le potentiel de l'IA et de la robotique travaillant ensemble. Notre objectif était d'apprendre à Spot à dessiner des objets sur la base de commandes vocales, une tâche combinant des composants complexes tels que la reconnaissance vocale, la génération d'images et le contrôle robotique précis.
Le défi
Notre principal défi était de permettre à Spot d'interpréter une commande audio, puis de dessiner l'objet correspondant en utilisant des modèles de diffusion. Cela nous a obligés à aborder plusieurs composants clés :
- Capture audio et reconnaissance vocale
- Génération de contours d'images
- Conversion des contours en G-code
- Intégration avec les capacités de dessin de Spot
G-code : le langage des machines CNC
Pour comprendre comment nous avons prévu de contrôler le bras de dessin de Spot, il est essentiel de saisir ce qu'est le G-code. Le G-code est un langage utilisé pour donner des instructions aux machines CNC et aux imprimantes 3D sur la manière de se déplacer. Il comprend des commandes pour divers types de mouvements et de contrôles, tels que :
Pour notre projet, nous nous sommes concentrés sur les commandes prises en charge par le SDK de Spot, à savoir G00, G01, G02, G03 et M0.
Étape 1 : Reconnaissance vocale avec Whisper et OpenAI
Pour donner des instructions à Spot sur ce qu'il doit dessiner, nous avions besoin d'un système de reconnaissance vocale efficace. Nous avons choisi le modèle de base de Whisper pour convertir les mots parlés en texte. Whisper a fourni des performances robustes, bien que nous ayons rencontré quelques problèmes avec les accents français. Ces défis, cependant, n'étaient pas insurmontables, et Whisper a capturé avec succès les commandes nécessaires à partir de notre discours.
Avec les commandes textuelles en main, nous avons utilisé GPT-4o d'OpenAI pour interpréter l'intention derrière le texte. GPT-4o a extrait l'objet spécifique que nous voulions que Spot dessine, fournissant une directive claire pour les étapes suivantes.
Étape 2 : Génération de SVG avec Stable Diffusion XL
Une fois l'objet identifié, la tâche suivante consistait à générer un simple contour de l'image. Nous avons utilisé Stable Diffusion XL, un puissant modèle de diffusion textuel à image open-source, pour créer ces contours. En utilisant Modal, nous avons configuré un point de terminaison d'inférence en quelques minutes seulement à l'aide d'un GPU A10G. Grâce à ce point de terminaison, nous avions désormais la capacité de générer une image de n'importe quel objet tout en essayant d'imposer un certain style qui nous permettrait d'extraire un contour à transformer en SVG.
Le post-traitement de l'image impliquait plusieurs étapes utilisant OpenCV :
Étape 3 : Amélioration de la cohérence avec une élection propulsée par un LLM
Pour surmonter les problèmes de cohérence inhérents aux modèles de diffusion généralistes comme Stable Diffusion XL, nous avons inclus un module d'évaluation. Cette approche consistait essentiellement à forcer un contour en générant plusieurs images simultanément. Parmi les quatre générations d'images, il y avait généralement une ou deux images suffisamment bonnes pour que Spot puisse les dessiner. Nous avons généré ces quatre images en parallèle et utilisé les fonctionnalités multimodales de GPT-4o pour déterminer quelle image était à la fois la plus facile à dessiner et la plus similaire à l'objet original.
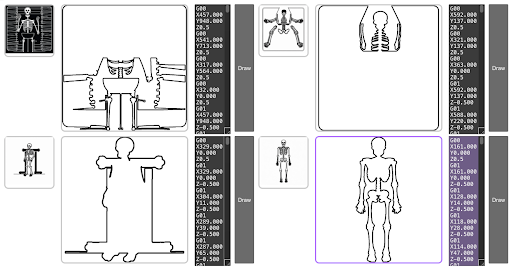

Étape 4 : Conversion de SVG en G-code
Une fois que nous avions un contour clair au format SVG, l'étape suivante consistait à le convertir en G-code. Nous avons développé une fonction de conversion SVG en G-code sur mesure en utilisant svgpathtools pour lire les chemins avec précision. Un défi majeur auquel nous avons été confrontés était le grand nombre de lignes de G-code générées à partir des chemins SVG détaillés. La quantité excessivement élevée d'instructions G-code entraînait de nombreux bégaiements de la part de Spot. Pour gérer cela, nous avons initialement mis en œuvre une stratégie de saut sélectif de lignes, assurant un équilibre entre précision de dessin et simplicité. Après des recherches supplémentaires, nous avons adopté l'algorithme Ramer-Douglas-Peucker, un algorithme de réduction de points itératif qui simplifie le nombre de points dans une ligne en trouvant des segments de ligne plus longs similaires.
.gif)
Étape 5 : Intégration avec Spot
La dernière étape consistait à envoyer le G-code à Spot pour qu'il dessine. Nous avons commencé avec l'exemple arm_gcode de Boston Dynamics, en ajoutant une couche API pour déclencher le processus de dessin depuis notre interface utilisateur.
En plus de la composante logicielle, nous devions également fixer un marqueur à la pince de Spot (bras). Heureusement, Robin avait déjà travaillé sur des projets similaires et disposait de quelques composants imprimés en 3D qui nous ont permis d'atteindre ce dont nous avions besoin. Bien que cela fonctionnait pour notre PoC, cela posait quelques problèmes.
Étant donné que le marqueur était fixé à Spot sans aucune flexibilité, nous heurtions souvent le marqueur au sol et la friction supplémentaire rendait difficile pour Spot de suivre le chemin fourni. Cela a entraîné des dessins moins soignés que nous ne le souhaitions. Nous nous sommes permis d'étendre le projet au-delà des limites de notre hackathon pour tenter de résoudre ce problème. La solution était relativement simple : ajouter un ressort au marqueur ou à l'outil de dessin pour permettre une certaine flexibilité.
Pour ce faire, Robin s'est tourné vers Fusion 360 pour concevoir une pièce cylindrique, qui tiendrait un "bâton de peinture lavable" avec un ajustement par friction pour permettre l'échange de couleurs, fixé avec un ressort. Le changement de média de dessin et le ressort permettent de réduire la friction contre notre toile, ce qui se traduit par un dessin plus fluide.



Après quelques essais et erreurs et des ajustements minutieux, nous avons réussi à permettre à Spot de dessiner des objets sur la base de commandes vocales!

Surmonter les Défis
Tout au long du hackathon, nous avons été confrontés à plusieurs défis, nécessitant chacun des solutions innovantes :
- Reconnaissance vocale : Les accents ont posé des difficultés initiales, mais la robustesse de Whisper nous a permis de capturer les commandes efficacement.
- Cohérence des images : Générer des images cohérentes et dessinables avec Stable Diffusion XL a nécessité un ajustement fin.
- Complexité du G-code : La gestion du grand nombre de lignes de G-code était cruciale pour assurer une performance fluide de Spot.
- Friction du marqueur : Ajouter une flexibilité au marqueur a été essentiel pour permettre à Spot de dessiner sans heurts.
Démonstrations et résultats
Malgré les difficultés, les résultats ont été impressionnants. Spot, affectueusement surnommé « Spot Ross », a réalisé plusieurs dessins à partir de nos commandes vocales. Ces démonstrations ont mis en évidence le potentiel de l'intégration de l'IA et de la robotique dans les applications créatives.



.gif)
Le hackathon a témoigné des progrès rapides de l'IA et de la robotique. En seulement 16 heures, nous avons réussi à combiner différents modèles d'IA et éléments robotiques pour obtenir des résultats remarquables. Pour l'avenir, nous souhaitons affiner notre prototype en perfectionnant le modèle de diffusion pour obtenir des générations plus cohérentes, en explorant les capacités de dessin vertical et les projets à plus grande échelle utilisant la craie. En outre, si nous disposons de plus de temps, l'extraction du sujet à l'aide d'une segmentation sémantique permettrait d'obtenir de bien meilleurs résultats et nous prévoyons d'explorer cette voie plus avant.
Un grand merci à Osedea et à Modal Labs pour leur soutien à ce projet innovant. L'avenir de l'IA et de la robotique est incroyablement prometteur, et nous sommes impatients de continuer à repousser les limites du possible.
Cet article vous a donné des idées ? Nous serions ravis de travailler avec vous ! Contactez-nous et découvrons ce que nous pouvons faire ensemble.



.jpg)


