Perspectives
Nous ne nous contentons pas d’être de simples spectateurs. Nous façonnons l’avenir. Plongez dans nos réflexions sur l’innovation, l’ingéniosité humaine, la technologie, la productivité et la culture d’entreprise.
Osedea et Mila annoncent un partenariat pour contribuer à l’innovation et à l’adoption de l'IA au Québec

Montréal, le 10 avril 2024 - Mila est fier d'annoncer un nouveau partenariat stratégique avec Osedea. Ensemble, ils s'engagent à combiner leurs expertises pour contribuer à l'écosystème technologique du Québec et à promouvoir l'adoption de l'IA dans les entreprises.
Cette collaboration permettra à Osedea d'accéder aux recherches de pointe de Mila, consolidant sa position en tant qu'acteur majeur de la transformation numérique au Québec. De plus, en recrutant des stagiaires parmi les étudiant·e·s et chercheur·euse·s de Mila et en participant aux événements de recrutement organisés par Mila, Osedea renforcera son équipe et son engagement envers l'innovation. Ensemble, ils contribueront à l’écosystème dynamique d'innovation technologique et de développement de talents en IA au Québec. Ce partenariat témoigne de l'engagement commun d'Osedea et Mila en faveur de l'innovation, de l'excellence et de la formation de main-d’œuvre qualifiée dans le domaine de la technologie.
« Nous sommes ravis de nous associer à Mila dans cette démarche visant à stimuler l'innovation technologique au Québec, a déclaré Martin Coulombe, président d'Osedea. Ce partenariat nous permettra de renforcer notre leadership en matière d’ingénierie logiciel tout en contribuant activement à l'avancement de l'IA pour améliorer la productivité de nos entreprises dans les domaines manufacturier, minier et de la santé. Ensemble, nous sommes déterminés à créer un impact positif et durable dans le domaine de la technologie. »
« Mila est ravi d'accueillir Osedea dans sa communauté de partenaires. Dans le cadre de cette collaboration, nous sommes heureux de pouvoir mettre en relation Osedea avec les chercheur·euse·s et talents en IA de classe mondiale de Mila, afin de contribuer ensemble à l’innovation et à l’adoption de l'IA au Québec, » a déclaré Stéphane Létourneau, vice-président exécutif de Mila.
À propos de Mila
Fondé par le professeur Yoshua Bengio de l’Université de Montréal, Mila est le plus grand centre de recherche universitaire en apprentissage profond au monde, rassemblant plus de 1 200 chercheur·euse·s spécialisé·e·s dans le domaine de l’apprentissage automatique. Basé à Montréal et financé en partie par le gouvernement du Canada dans le cadre de la Stratégie pancanadienne en matière d'IA, Mila a pour mission d’être un pôle mondial d’avancées scientifiques qui inspire l’innovation et le développement de l’IA au bénéfice de tous·tes. Mila est une organisation à but non lucratif reconnue mondialement pour ses importantes contributions au domaine de l’apprentissage profond, en particulier dans les domaines de la modélisation du langage, de la traduction automatique, de la reconnaissance d’objets et des modèles génératifs. Pour en savoir plus, visitez mila.quebec.
À propos d’Osedea
Osedea est une firme d’innovation basée à Montréal, spécialisée dans la création de solutions technologiques sur mesure pour les entreprises. Fondée en 2011, Osedea se distingue par son expertise en intelligence artificielle, en robotique, en ingénierie logiciel et en design de l’expérience utilisateur (UX/UI), en plus de son approche centrée sur l'innovation et la collaboration avec ses client·e·s. Pour en savoir plus, visitez www.osedea.com.
Naviguer l'innovation à Hannover Messe 2024
Pour la deuxième année consécutive, j'ai eu la chance de participer à la Hannover Messe, le plus grand salon mondial de la technologie dans le secteur manufacturier. L'édition 2024 se distinguait nettement de celle de 2023, notamment par une présence accrue du Canada, avec des stands répartis dans quatre grandes salles et une promotion importante de son rôle de pays hôte partenaire pour 2025.
Fort de mon expérience de l'année dernière, j'étais mieux outillé pour me frayer un chemin à travers les immenses salles d'exposition—où tant de choses excitantes se produisent simultanément—et à optimiser mon temps. Voici ce que j'en retiens.
Notre projet mis en lumière sur la plus grande scène mondiale
Nous sommes fiers de collaborer au projet KonnectAi de Promark Electronics, un système d'inspection visuelle de qualité en cours de processus et finale, alimenté par des algorithmes de vision par ordinateur et une technologie de pointe. Pour célébrer son lancement monumental, notre client Jarred Knecht (président de Promark et de KonnectAi) a pris place au centre de la scène pour promouvoir l'accessibilité à l'IA et présenter KonnectAi au stand de Google Cloud (le partenaire cloud qui pilote la technologie). Une expérience impressionnante et une occasion inégalée pour cette nouvelle innovation de séduire de nouveaux clients.


Virage numérique, virage durable
Les thèmes de ClimateTech et de durabilité étaient omniprésents lors de l'événement. Encore une fois cette année, Siemens a été à l'avant-garde de ces efforts, présentant une gamme de cleanTech et de solutions potentielles à travers leur espace. Ils se vantent d'avoir le plus grand et le plus impressionnant stand de toute la Hannover Messe. Petit fait amusant : Siemens dépense la somme stupéfiante de 32 millions de dollars par an pour assembler et entretenir ce stand, qui sert également de showroom fixe toute l'année.
Siemens a principalement mis en avant trois solutions clés pour lutter contre la crise climatique : leurs produits EcoTech, les usines durables et des solutions de durabilité complètes. Ces initiatives s'alignent sur la vision de Siemens d'atteindre la neutralité carbone à l'échelle mondiale d'ici 2030. De l'utilisation de jumeaux numériques au recyclage des pneus dans une économie circulaire, une multitude de technologies innovantes ont été exposées pour soutenir cet objectif.
Un exemple frappant de ces solutions durables est PlantSwitch, une startup qui utilise les technologies de Siemens pour transformer les plantes en plastiques. La beauté de cette innovation réside dans le fait que tous les produits finaux sont compostables. Au total, Siemens a développé 37 produits EcoTech, dont sept ont été présentés à la Hannover Messe.

IA et XR partout
Cette année encore, l'IA était omniprésente. Il est clair que les entreprises qui n'investissent pas encore ou ne prévoient pas d'utiliser l'IA pour améliorer leur efficacité risquent de se retrouver désavantagées à l'avenir. Comme le recommande Jarred Knecht, il encourage toutes les entreprises manufacturières à entamer leur parcours IA avec un petit projet. Souvent, cela représente un investissement minimal pour les entreprises, grâce à divers programmes de soutien offerts aux entreprises manufacturières tels que le SIPEM, l'IRAP et l'ESSOR, pour n'en nommer que quelques-uns.
Une entreprise qui s'est distinguée lors de l'événement est iGus, qui a habilement fusionné l'IA avec la durabilité. En intégrant la technologie et l'IA, ils ont réussi à éliminer les lubrifiants des moteurs — une innovation cruciale puisqu'un seul litre d'huile lubrifiante peut contaminer un million de litres d'eau potable.
J'ai également eu l'occasion d'essayer les nouveaux casques Meta Quest XR. Encore une fois, les technologies XR ont fait un bond significatif en avant cette année ! Il est remarquable de voir à quel point cette technologie est devenue conviviale pour les entreprises de fabrication et de conception. La XR permet aux ingénieurs et aux concepteurs de prototyper et de visualiser les produits dans un espace virtuel, améliorant la collaboration et accélérant le processus d'itération avant la production physique. Cela non seulement rationalise le processus de conception, mais réduit également considérablement le temps de mise sur le marché.

Vers le futur
En conclusion, si vous avez un vif intérêt pour la technologie industrielle, l'automatisation, la R&D, et que vous voulez être époustouflé par les possibilités futures, la Hannover Messe est un événement à ne pas manquer. Pour les entreprises canadiennes, l'édition 2025 revêt une importance particulière, puisque le Canada sera le pays hôte partenaire honoré. Ce rôle spécial mettra en vedette un pavillon central présentant plus de 200 organisations canadiennes de premier plan, accompagné d'un programme de conférences quotidien incluant des présentations de produits et de technologies sur scène. Ce sera une occasion en or pour le Canada de mettre en avant ses innovations industrielles et technologiques, de favoriser de nouveaux partenariats et de façonner les industries de l'avenir.

On se voit en 2025.
Adopter la clarté et la structure : mise en œuvre du Modèle C4 pour les diagrammes d'architecture logicielle

Dans le paysage toujours changeant du développement logiciel, notre équipe de conception et de qualité logicielle (SDQT) chez Osedea cherche continuellement des moyens d'affiner nos flux de travail de développement. Chaque mois, nous nous réunissons pour engager des discussions approfondies sur les dernières tendances technologiques émergentes. Que ce soit en plongeant dans les analyses modernes des compromis dans les architectures distribuées ou en restant à jour avec les nouveaux outils et frameworks, nous nous efforçons de maintenir notre agilité dans notre cycle de développement logiciel. Cet article explore les avantages du modèle C4 en matière de communication technique, mettant en lumière son approche descriptive, son utilisation de couleurs contrastées, ainsi que sa capacité à rationaliser le processus de documentation. De plus, il propose des conseils pratiques pour démarrer avec le modèle C4 et souligne son impact transformateur sur la présentation des aspects techniques des projets aux clients.
Il y a quelques mois, nous avons introduit le modèle C4 de Simon Brown dans nos discussions. Après avoir expérimenté le modèle à plusieurs reprises, nous avons rapidement réalisé que ce modèle devrait devenir une norme dans notre approche de création de diagrammes architecturaux. La transition de nos méthodes traditionnelles à cette nouvelle approche n'était pas simplement un changement de technique, mais un changement significatif dans notre perception et notre communication des conceptions de systèmes complexes.
Qu’est-ce que le modèle C4 ?
Le modèle C4, basé sur le modèle de vue architecturale 4+1, peut être comparé à une carte multi-couches pour l'architecture logicielle. Il nous permet de visualiser un système à différents niveaux d'abstraction, de manière similaire à la navigation sur Google Maps - depuis une vue aérienne du monde jusqu'aux rues et aux bâtiments individuels. Dans le modèle C4, chaque "C" représente un type de modèle différent à un niveau de détail différent. Ces différents niveaux sont connus sous le nom de contexte, de conteneurs, de composants et de code :




- Contexte : Il s'agit du niveau le plus élevé du modèle, fournissant une vue d'ensemble du système. Il montre comment le système logiciel interagit avec ses utilisateurs et d'autres systèmes. C'est essentiel pour comprendre les limites du système et ses relations avec les entités externes. Ce niveau est destiné à être adapté à tous les parties prenantes, y compris les utilisateurs non techniques.

- Conteneurs : À ce niveau, l'accent est mis sur les applications et les magasins de données (comme les bases de données, les systèmes de fichiers, etc.) qui composent le système. Il illustre comment ces conteneurs interagissent les uns avec les autres et les responsabilités qu'ils ont au sein du système. Ce niveau est crucial pour comprendre les choix technologiques de haut niveau et la structure du système.

- Composants : À ce niveau, les conteneurs sont décomposés en leurs composants constitutifs, détaillant les responsabilités de ces composants et comment ils interagissent les uns avec les autres. Il est utile pour les développeurs et d'autres personnes impliquées dans le processus de construction et de conception, car il offre une vue plus détaillée de l'architecture du système.

- Code : C'est le niveau le plus granulaire, se concentrant sur les classes et interfaces individuelles qui composent les composants. Ce niveau est particulièrement pertinent pour les développeurs qui ont besoin de comprendre en détail la structure interne et la conception des différents composants. La plupart des IDE disposent d'outils permettant de générer ces diagrammes.
À ce stade, vous vous demandez probablement pourquoi le code fait partie d'un diagramme architectural. La beauté de ce modèle est que vous choisissez à quel niveau de granularité vous voulez vous arrêter. La plupart du temps, la partie code est laissée de côté dans ces diagrammes. Pour les présentations clients, nous avons constaté que les première et deuxième couches suffisent à fournir un aperçu détaillé de l'architecture. La troisième couche est utile avant la phase de mise en œuvre pour planifier les détails les plus fins.
Quels sont les avantages du modèle C4 ?
Fondamentalement, le modèle C4 aborde un problème essentiel de la communication technique : la transmission de l'information. Souvent, les diagrammes techniques sont encombrés d'icônes spécifiques à la technologie, ce qui, bien que informatif pour certains, peut être déroutant pour d'autres. Le modèle C4 plaide en faveur d'une approche plus descriptive. Au lieu de s'appuyer sur des symboles qui pourraient être familiers à seulement une partie de l'équipe, il encourage les explications de ce que fait chaque technologie. Cette approche garantit que tout le monde, quel que soit son niveau de familiarité avec des technologies spécifiques, puisse comprendre l'architecture.
Le modèle C4 met également l'accent sur l'utilisation de couleurs contrastées au lieu de s'appuyer uniquement sur des codes de couleur, rendant les diagrammes compréhensibles même lorsqu'ils sont imprimés en noir et blanc. Cette considération garantit que les diagrammes restent efficaces et clairs dans différentes conditions de visualisation, y compris sur des écrans numériques et des impressions physiques.
De plus, le modèle C4 rationalise le processus de documentation en fournissant un cadre clair et concis. Cela est particulièrement bénéfique pour les systèmes complexes où une documentation détaillée est cruciale. En délimitant différents niveaux du système, du contexte jusqu'au niveau du code, le modèle C4 facilite la création d'une documentation complète et structurée, facilement compréhensible et maintenable.
Comment commencer avec le modèle C4 ?
En termes d'outils pour concevoir des diagrammes C4, des outils comme Structurizr et Mermaid.js, qui prennent en charge l'approche "C4 model as code", sont souvent recommandés. Cette méthode est avantageuse pendant la phase de développement car elle facilite la maintenance et les mises à jour des diagrammes. Bien que le C4 en tant que code soit préféré pour son approche automatisée et maintenable, nous avons remarqué que d'autres outils comme draw.io peuvent également être bénéfiques. Malgré son caractère manuel et potentiellement fastidieux, draw.io permet de créer des diagrammes esthétiquement plaisants, adaptés aux présentations clients.
L'implémentation du modèle C4 a transformé la manière dont nous présentons les aspects techniques des projets à nos clients. Cela leur permet de choisir le niveau de détail avec lequel ils souhaitent interagir. Cette flexibilité améliore leur compréhension et permet des discussions plus significatives sur le projet.
Alors que nous avançons, notre engagement chez Osedea est d'intégrer le modèle C4 dans tous nos processus architecturaux. Nous croyons que cette approche améliorera notre efficacité et notre clarté dans la conception logicielle. Restez à l'écoute pour de futures mises à jour et réflexions de notre équipe SDQT alors que nous progressons régulièrement dans le paysage technologique en constante évolution. Pour ceux qui souhaitent faire évoluer leur architecture logicielle ou cherchent des conseils sur les méthodologies de développement modernes, Osedea est là pour vous aider. N'hésitez pas à nous contacter pour une discussion sur la manière dont nous pouvons soutenir vos objectifs de développement logiciel avec notre expertise et notre expérience.
Portraits Osedea : IA, aventures et culture avec Isabelle Bouchard

Dans le cadre de notre série Portraits d'Osedea, rencontrez aujourd'hui Isabelle Bouchard, développeuse senior et spécialiste en machine learning. Animée par une insatiable curiosité, Isabelle explore avec passion le monde de l'IA et ses applications pour le bien-être de tous. Au-delà de son expertise aiguisée, découvrez une femme pétillante et inspirante qui nous fera partager ses passions et les multiples facettes de sa personnalité.
D'où vient ton intérêt pour la science et l’intelligence artificielle ?
C’est un peu par hasard (ou par chance !) que je me suis orientée vers une carrière en intelligence artificielle. Au départ, j’ai étudié en génie biomédical. À la fin de mes études, bien que j'aie eu un intérêt, j'avais très peu d’expérience en développement logiciel et encore moins en intelligence artificielle. En fait, je n'avais jamais entendu parler du concept de machine learning (ML) avant d'en explorer les techniques dans mon premier emploi.
J’ai tout de suite aimé le fait que cela demande à la fois des compétences en mathématiques et en développement logiciel, ainsi qu'une bonne capacité à décomposer un problème. J'ai parcouru un petit bout de chemin en autodidacte, soutenue par des collègues qui m'ont beaucoup aidée à progresser. J'ai ensuite décidé de faire une maîtrise pour formaliser mes apprentissages et développer une expérience de recherche.

Qu’est-ce qui te passionne le plus en IA ?
J’apprécie particulièrement le dynamisme de ce domaine, qui évolue très rapidement. Je suis constamment mise au défi et je dois apprendre de manière continue pour pouvoir rester à jour avec les technologies.
De plus, les applications de l’IA sont infinies, ce qui me permet d’explorer de nouveaux domaines d'application. Ces dernières années, j'ai travaillé sur des projets en santé, en agriculture, en urbanisme, et bien d’autres domaines. C’est extrêmement stimulant.
Dans des secteurs de pointe comme l’intelligence artificielle, les femmes ne représentent que 22 % des professionnels. De plus, les femmes ne représentent que 28 % des diplômés en ingénierie et 40 % des diplômés en informatique. Selon toi, qu’est-ce qui explique le faible nombre de femmes en technologie, en ingénierie et en intelligence artificielle ?
Il y a plusieurs raisons pour lesquelles les femmes choisissent des domaines autres que ceux des technologies, mais il est clair pour moi que l’absence de modèles féminins en est une qui pèse lourd dans la balance. Cela explique également pourquoi plusieurs femmes choisissent de quitter le domaine, où elles ne se sentent pas toujours à leur place. On développe naturellement des affinités avec les personnes qui nous ressemblent, donc il est parfois plus difficile de trouver des alliés ou des mentors lorsqu’on est une femme dans un milieu occupé en majorité par des hommes. On a aussi une idée préconçue assez bien définie du développeur type, et cela peut faire peur quand on ne s’y identifie pas. Personnellement, cela m’a longtemps affectée, mais j’ai appris avec le temps à reconnaître que, clairement, je ne correspondrai jamais à ce profil, mais que c’est plus souvent vu comme une force qu’une faiblesse.
Comment envisages-tu l'impact de l'IA et de l'apprentissage automatique sur les industries dans les années à venir, en particulier dans des domaines tels que la santé, la finance et la technologie ?
J’espère voir l’IA assister les humains, plutôt que les remplacer, surtout en santé. Nos systèmes manquent de plus en plus d’humanité, et j’espère que nos dirigeants seront en mesure de comprendre comment utiliser les technologies pour nous rendre plus efficaces, mais sans perdre de vue l’importance des rapports humains. On comprendra que je ne suis pas nécessairement du genre optimiste ! L’IA et les technologies en général offrent des possibilités infinies, encore faut-il savoir les utiliser à bon escient.
Comment l’équipe IA chez Osedea intègre-t-elle les principes éthiques dans la conception et le déploiement de solutions basées sur l'IA ?
L’éthique des projets d’IA repose encore en grande partie sur les personnes qui les développent. Je répondrais donc spontanément que tout commence par l’embauche de personnes qui ont ces enjeux à cœur. Ensuite, dans notre processus d’analyse des besoins d’un projet, nous avons plusieurs points de contrôle pour nous assurer de soulever et de mitiger les principaux risques éthiques. Par exemple, nous analysons les jeux de données utilisés pour l'entraînement de nos modèles d’IA pour nous assurer de ne pas favoriser un segment d’utilisateurs au détriment d’un groupe sous-représenté dans les données.
Quelle serait ta retraite idéale ?
En santé ! J’adore le plein air. J’aimerais avoir une retraite remplie d’aventures qui me permettraient de continuer à me dépasser physiquement et mentalement, et à m'émerveiller devant la nature. Le tout accompagné de mon partenaire d’aventure préféré, de notre famille et de nos amis… et, bien sûr, entrecoupé de bons moments de détente !

As-tu un film ou un livre coup de cœur à recommander, et pourquoi ?
Puisqu’on vient de terminer la saison des Oscars, je ne peux pas passer à côté du merveilleux film "Poor Things", avec l’incroyable performance de l’actrice Emma Stone. Je le recommande fortement, comme tous les films de Yorgos Lanthimos, pour le scénario recherché et les personnages complètement déstabilisants.
Je recommande également la lecture du classique de la littérature américaine "Les Raisins de la Colère", de John Steinbeck. C'est un roman qui a été publié en 1939, mais qui raconte de manière très juste et toujours actuelle l’expérience humaine de ceux qui perdent à la loterie de la vie et qui se retrouvent du côté de la misère. Ce roman m’a profondément marquée.
Quelle est ta meilleure et ta pire habitude ?
Ma meilleure habitude, c’est d’être active. C’est un effort constant, mais ça m’est tellement bénéfique que j'en fais une priorité au quotidien. Ma pire habitude...procrastiner, clairement !

Quel est ton plus beau voyage et pourquoi ?
Un voyage en Turquie, en 2015, alors que je venais de terminer mon baccalauréat. Pour la richesse de la culture, les paysages grandioses et les villes absolument vibrantes, mais surtout pour l’incroyable sentiment de liberté que j’ai eu la chance de vivre en voyageant au début de la vingtaine. Sans un sou ni contrainte de temps, on se laissait réellement porter par les rencontres et les opportunités qui s’offraient à nous. Je sais que jamais je ne pourrai reproduire de pareilles circonstances, c’était magique !

Si tu pouvais posséder une compétence instantanément, laquelle choisirais-tu et comment l'utiliserais-tu dans ta vie quotidienne ?
J'aimerais posséder une aisance à m’exprimer à l’oral, sur le vif, de façon claire et concise. J’admire vraiment les gens qui le font naturellement ! Et c’est simple, j’appliquerais cette compétence dans toutes les sphères de ma vie, tant au niveau personnel que professionnel. La communication est tellement importante dans toutes les relations qu’on entretient. Ce qui serait magique, ce serait d'être capable de le faire en plusieurs langues !
La Transformation de l'Agriculture Verticale avec le Robot Spot chez Interius Farms

Le Contexte
Dans sa quête d'innovation et de pratiques durables, Interius Farms, un leader dans l'innovation AgTech, s'est associé à Osedea pour explorer le potentiel de la détection dynamique et de la robotique mobile dans l'agriculture verticale. Cette collaboration vise à apporter efficacité, automatisation et précision à la culture de légumes-feuilles et d'herbes tout en privilégiant la responsabilité environnementale.
La Puissance de la Robotique Avancée et de l'IA dans l'Agriculture Verticale
Interius Farms est à l'avant-garde de l'innovation en agriculture, utilisant des technologies avancées pour révolutionner les pratiques agricoles traditionnelles. En exploitant la plateforme de détection mobile d'Osedea, le robot Spot, ils peuvent intégrer la robotique avancée et l'IA dans leurs opérations. Le robot Spot navigue dans la ferme de manière autonome, collectant des données et surveillant la santé des plantes à l'aide de ses capteurs. Cette mission de détection dynamique permet des tâches de précision autour de l'horloge et garantit une collecte de données précise, éliminant ainsi le besoin de pratiques manuelles et sujettes aux erreurs.

Créer un Avenir Durable avec la Technologie
L'engagement d'Interius Farms envers la durabilité s'aligne parfaitement avec la vision d'Osedea pour un avenir meilleur. En mettant en œuvre des technologies avancées telles que la robotique, l'IA et l'analyse de données, Interius Farms maximise l'efficacité et minimise la consommation de ressources. Grâce à leur système hydroponique, ils utilisent 95 % moins d'eau et 92 % moins de terres que l'agriculture traditionnelle. De plus, leur environnement contrôlé et leurs systèmes d'éclairage optimisés réduisent la consommation d'énergie, rendant leur ferme verticale plus éco-énergétique.
Le Rôle d'Osedea dans la Transformation Numérique de l'AgTech
Osedea apporte bien plus que la simple livraison de logiciels. En tant que fournisseur de solutions, nous comprenons les besoins uniques et les défis des entreprises dans des secteurs industriels tels que l'AgTech. Notre expertise réside dans la création de solutions logicielles sur mesure adaptées à des exigences spécifiques. En combinant notre compétence en robotique, en IA et en analyse de données, Osedea permet aux entreprises d'atteindre la transformation numérique et de libérer tout le potentiel des avancées technologiques. Leur focus sur l'utilisabilité, l'innovation et les concepts novateurs repousse les limites de ce que l'efficacité numérique peut apporter à l'industrie AgTech.

La suite...
Le déploiement du robot Spot d'Osedea chez Interius Farms constitue une étape significative vers la révolution de l'agriculture verticale. Interius Farms peut atteindre une efficacité, une productivité et une durabilité améliorées en intégrant la robotique avancée, l'IA et des solutions logicielles sur mesure. La collaboration entre Interius Farms et Osedea démontre la puissance des partenariats et de l'innovation basée sur la recherche pour induire un changement positif.
En adoptant la technologie dure et en tirant parti des capacités transformatrices de la robotique avancée et de l'IA, des entreprises comme Interius Farms ouvrent de nouvelles voies vers un avenir plus durable. La combinaison de l'agriculture verticale, de l'AgTech, de la robotique et de l'IA permet aux leaders de devenir des architectes de données, leur permettant de prendre des décisions éclairées et d'optimiser leurs opérations.
Alors que nous regardons vers l'avenir, il est clair que la collaboration continue et l'application stratégique des technologies de pointe alimenteront de nouveaux progrès dans l'industrie AgTech. Interius Farms et Osedea façonnent l'avenir de l'agriculture, une percée à la fois, et favorisent un monde où l'innovation et la durabilité vont de pair.
"
Approche minimaliste de DataOps et MLOps avec DVC et CML
Dans cet article, nous examinerons l'importance cruciale de DataOps et MLOps dans le développement logiciel et en IA. Nous présenterons une approche MVP pratique, mettant l'accent sur l'utilisation de DVC (Contrôle de Version de Données) et CML (Apprentissage Automatique Continu), intégrés à Git, pour illustrer efficacement ces concepts.
- Approche Pratique : En utilisant DVC et CML, nous démontrerons une approche pratique de produit minimal viable (MVP) pour DataOps et MLOps.
- Intégration avec Git : En mettant en évidence l'intégration fluide de ces outils avec Git, nous montrerons comment les flux de travail familiers peuvent être améliorés pour la gestion des données et des modèles.
- Implémentation Efficace : Notre objectif est de fournir des directives claires pour implémenter efficacement les pratiques DataOps et MLOps.
Problèmes Courants dans les Projets AI & Data
- "Quelle Version de Données ?" Perdez-vous constamment la trace de la version de données utilisée pour l'entraînement du modèle ?
- "Le Nouveau Modèle Est-il Bon ?" Arrêtez de vous demander si votre dernier modèle bat l'ancien ou ce qui a changé entre eux.
- "Pourquoi Notre Dépôt Est-il Si Lourd ?" Dépôt GitHub surchargé avec des données ?
Compréhension de DataOps et MLOps
DataOps et MLOps sont des pratiques fondamentales pour le développement logiciel moderne, en particulier en IA. Ces approches sont essentielles pour gérer efficacement les cycles de vie des données et des modèles d'apprentissage automatique.
- Scalabilité : Gérer efficacement les données (DataOps) et les modèles d'apprentissage automatique (MLOps) est essentiel pour construire des systèmes d'IA évolutifs et robustes, cruciaux pour les projets de développement logiciel.
- Performance et Fiabilité : La mise en œuvre de ces pratiques garantit des performances système constantes et une fiabilité, ce qui est particulièrement vital pour les start-ups opérant dans des environnements dynamiques et contraints en ressources.
- Éviter les Pièges : De nombreuses équipes de développement ont besoin de versionner correctement les données et les modèles ou adoptent une approche réactive de la gestion système, ce qui entraîne des défis significatifs en matière de reproductibilité et d'augmentation des taux d'erreur, entravant la croissance et l'innovation.
Comprendre et intégrer DataOps et MLOps dans les flux de travail n'est pas seulement bénéfique ; c'est une nécessité stratégique.
L'Approche MVP
L'approche MVP (Produit Minimal Viable) en DataOps et MLOps consiste à s'aligner sur les principes fondamentaux du Manifeste Agile, en mettant l'accent sur la simplicité, l'efficacité et le déploiement.
- Principes Agiles : Mettez l'accent sur la simplicité, l'efficacité et les processus axés sur les personnes, favorisant la flexibilité et la réactivité dans la gestion de projet.
- Réduire la Dépendance aux Systèmes Complexes : Plaidez pour une minimisation de la dépendance aux systèmes SaaS complexes et propriétaires, maintenant ainsi le contrôle et la flexibilité dans votre développement.
- Outils Efficaces : Exploitez des outils comme DVC et CML qui s'intègrent avec les flux de travail Git familiers ; cette approche garantit une adoption fluide et améliore la collaboration et l'efficacité de l'équipe.
Adopter une approche MVP signifie créer des flux de travail en DataOps et MLOps plus agiles, adaptables et efficaces, permettant le développement de solutions robustes et évolutives sans être encombré par des complexités inutiles.
Pratique
Maintenant, nous plongeons dans les aspects pratiques de la mise en place d'un environnement Python et de l'utilisation d'outils essentiels comme DVC, CML et SciKit-Learn. Nous passerons par la configuration d'un dépôt GitHub pour un contrôle de version efficace et démontrerons la construction et l'évaluation d'un modèle en utilisant SciKit-Learn dans un calepin Jupyter.
- Configuration : Configurez un environnement Python et installez DVC, CML et SciKit-Learn.
- Construction de Modèle : Utilisez SciKit-Learn avec un ensemble de données intégré dans un calepin Jupyter pour une démonstration simple d'entraînement et d'évaluation de modèle.
- Processus Simplifié : Configurez GitHub et Git pour exécuter et évaluer votre modèle.
Installez l'Environnement Python
Nous utiliserons Poetry pour gérer notre environnement Python. Poetry est un outil de gestion de dépendances Python qui vous permet de créer des environnements reproductibles et d'installer facilement des packages.
# Install Poetry
pipx install poetry
# Init Poetry project
poetry init
# Add dependencies
poetry add dvc cml scikit-learn
Chargement des données
Nous utiliserons l'ensemble de données sur leBreast Cancer Data Set de UCI Machine Learning Repository.
Caractéristiques clés :
- Nombre d'Instances : 569
- Nombre d'Attributs : 30 attributs numériques prédictifs, plus la classe.
- Attributs : Mesures telles que le rayon, la texture, le périmètre, la zone, la régularité, la compacité, la concavité, les points concaves, la symétrie et la dimension fractale.
- Distribution des Classes : 212 Malignes, 357 Bénignes.
import sklearn.datasets
# Load dataset
data = sklearn.datasets.load_breast_cancer(as_frame=True)
print(data.data.info())
Mise en Œuvre de Paramètres Externes pour les Ajustements de Données et de ModèlesNous utiliserons des fichiers de configuration externes, comme settings.toml, pour ajuster dynamiquement les paramètres des données et du modèle. Cette approche ajoute de la flexibilité à notre projet et souligne l'importance de la versionnage et du suivi des changements, surtout lors de l'introduction de modifications intentionnelles ou de "bugs" à des fins de démonstration.
Dégradation des Données avec des Paramètres Externes
Parce que l'ensemble de données de démonstration fonctionne bien avec un modèle simple, nous allons dégrader artificiellement les données pour souligner l'importance du suivi des changements et de la versionnage.
- Configuration Externe : Utilisez settings.toml pour définir des paramètres comme num_features=1, qui dicte le nombre de fonctionnalités à utiliser à partir de l'ensemble de données.
- Manipulation des Données : Nous modifions dynamiquement nos données en lisant le paramètre num_features depuis settings.toml. Par exemple, en réduisant l'ensemble de données à une seule fonctionnalité :
python
import toml
settings = toml.load("settings.toml")
data.data = data.data.iloc[:, : settings["num_features"]]
print(data.data.info())
Entraînement du Modèle
We'll use SciKit-Learn to split the data and train a simple model.
python
import sklearn.model_selection
# Split into train and test
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
data.data, data.target, test_size=0.3, random_state=42
)
python
import sklearn.linear_model
# Train a simple logistic regression model
model = sklearn.linear_model.LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
python
# Evaluate the model
predictions = model.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(y_test, predictions)
print(f"Model Accuracy: {accuracy:.2f}")
Model Accuracy: 0.91
python
# View the classification report
report = sklearn.metrics.classification_report(y_test, predictions)
print(report)
# Export the report to a file
with open("report.txt", "w") as f:
f.write(report)
precision recall f1-score support
0 0.93 0.83 0.87 63
1 0.90 0.96 0.93 108
accuracy 0.91 171
macro avg 0.92 0.89 0.90 171
weighted avg 0.91 0.91 0.91 171
python
import seaborn as sns
import matplotlib.pyplot as plt
# Create a confusion matrix
confusion_matrix = sklearn.metrics.confusion_matrix(y_test, predictions)
# Plot the confusion matrix
sns.heatmap(confusion_matrix, annot=True, fmt="d")
# Export the plot to a file
plt.savefig("confusion_matrix.png")
Saving the Model and Data
We'll save the model and data locally to demonstrate DVC's tracking capabilities.
python
from pathlib import Path
# Save data
Path("data").mkdir(exist_ok=True)
data.data.to_csv("data/data.csv", index=False)
data.target.to_csv("data/target.csv", index=False)
python
import joblib
# Save model
Path("model").mkdir(exist_ok=True)
joblib.dump(model, "model/model.joblib")
Implementing Data and Model Versioning with DVC
Until now, we have covered the standard aspects of AI and machine learning development. We're now entering the territory of data versioning and model tracking. This is where the real magic of efficient AI development comes into play, transforming how we manage and evolve our machine-learning projects.
- Better Operations: Data versioning and model tracking are crucial for AI project management.
- Data Versioning: Efficiently manage data changes and maintain historical accuracy for model consistency and reproducibility.
- Model Tracking: Start tracking model iterations, identify improvements, and ensure progressive development.
Streamlining Workflow with DVC Commands
To effectively integrate Data Version Control (DVC) into your workflow, we break down the process into distinct steps, ensuring a smooth and understandable approach to data and model versioning.
Initializing DVC
Start by setting up DVC in your project directory. This initialization lays the groundwork for subsequent data versioning and tracking.
dvc init
Setting Up Remote Storage
Configure remote storage for DVC. This storage will host your versioned data and models, ensuring they are safely stored and accessible.
dvc remote add -d myremote /tmp/myremote
Versioning Data with DVC
Add your project data to DVC. This step versions your data, enabling you to track changes and revert if necessary.
dvc add data
Versioning Models with DVC
Similarly, add your ML models to DVC. This ensures your models are also versioned and changes are tracked.
dvc add model
Committing Changes to Git
After adding data and models to DVC, commit these changes to Git. This step links your DVC versioning with Git's version control system.
git add data.dvc model.dvc .gitignore
git commit -m "Add data and model"
Pushing to Remote Storage
Finally, push your versioned data and models to the configured remote storage. This secures your data and makes it accessible for collaboration or backup purposes.
dvc push
Tagging a Version
Create a tag in Git for the current version of your data:
git tag -a v1.0 -m "Version 1.0 of data"
Updating and Versioning Data
- Make Changes to Your Data:
-Modify your data.csv as needed. - Track Changes with DVC:
-Run dvc add again to track changes:
dvc add data
- Commit the New Version to Git:
- -Commit the updated DVC file to Git:
git add data.dvc
git commit -m "Update data to version 2.0"
- Tag the New Version:
- -Create a new tag for the updated version:
git tag -a v2.0 -m "Version 2.0 of data"
Switching Between Versions
- Checkout a Previous Version:
- -To revert to a previous version of your data, use Git to checkout the corresponding tag:
git checkout v1.0
- Revert Data with DVC:
- -After checking out the tag in Git, use DVC to revert the data:
dvc checkout
Understanding Data Tracking with DVC
DVC offers a sophisticated approach to data management by tracking pointers and hashes to data rather than the data itself. This methodology is particularly significant in the context of Git, a system not designed to efficiently handle large files or binary data.
How DVC Tracks Data
- Storing Pointers in Git:
-DVC stores small .dvc files in Git. These pointers reference the actual data files.
-Each pointer contains metadata about the data file, including a hash value uniquely identifying the data version.
- Hash Values for Data Integrity:
-DVC generates a unique hash for each data file version. This hash ensures the integrity and consistency of the data version being tracked.
-Any change in the data results in a new hash, making it easy to detect modifications.
- Separating Data from Code:
-Unlike Git, which tracks and stores every version of each file, DVC keeps the actual data separately in remote storage (like S3, GCS, or a local file system).
-This separation of data and code prevents bloating the Git repository with large data files.
Importance in the Context of Git
- Efficiency with Large Data:
-Git struggles with large files, leading to slow performance and repository bloat. DVC circumvents this by offloading data storage.
-Developers can use Git as intended – for source code – while DVC manages the data.
- Enhanced Version Control:
-DVC extends Git's version control capabilities to large data files without taxing Git's infrastructure.
-Teams can track changes in data with the same granularity and simplicity as they track changes in source code.
- Collaboration and Reproducibility:
-DVC facilitates collaboration by allowing team members to share data easily and reliably through remote storage.
-Reproducibility is enhanced as DVC ensures the correct alignment of data and code versions, which is crucial in data science and machine learning projects.
Using DVC as a Feature Store
DVC can be a feature store in machine learning workflows. It offers advantages such as version control, reproducibility, and collaboration, streamlining the management of features across multiple projects.
What is a Feature Store?
A feature store is a centralized repository for storing and managing features - reusable pieces of logic that transform raw data into formats suitable for machine learning models. The core benefits of a feature store include:
- Consistency: Ensures uniform feature calculation across different models and projects.
- Efficiency: Reduces redundant computation by reusing features.
- Collaboration: Facilitates sharing and discovering features among data science teams.
- Quality and Compliance: Maintains a single source of truth for features, enhancing data quality and aiding in compliance with data regulations.
Benefits of DVC in Feature Management
- Version Control for Features: DVC enables version control for features, allowing tracking of feature evolution.
- Reproducibility: Ensures each model training is traceable to the exact feature set used.
- Collaboration: Facilitates feature-sharing across teams, ensuring consistency and reducing redundancy.
Setting Up DVC as a Feature Store
- Organizing Feature Data: Store feature data in structured directories within your project repository.
- Tracking Features with DVC: Use DVC to add and track feature files (e.g., dvc add data/features.csv).
- Committing Feature Changes: Commit changes to Git alongside .dvc files to maintain feature evolution history.
Using DVC for Feature Updates and Rollbacks
- Updating Features: Track changes by rerunning dvc add on updated features.
- Rollbacks: Use dvc checkout to revert to specific feature versions.
Best Practices for Using DVC as a Feature Store
- Regular Updates: Keep the feature store up-to-date with regular commits.
- Documentation: Document each feature set, detailing source, transformation, and usage.
- Integration with CI/CD Pipelines: Automate feature testing and model deployment using CI/CD pipelines integrated with DVC.
Implementing a DVC-Based Feature Store Across Multiple Projects
- Centralized Data Storage: Choose shared storage that is accessible by all projects and configure it as a DVC remote.
- Versioning and Sharing Features: Version control feature datasets in DVC and push them to centralized storage. Share .dvc files across projects.
- Pulling Features in Different Projects: Clone repositories and pull specific feature files using DVC, enabling their integration into various workflows.
Best Practices for Managing a DVC-Based Feature Store Across Projects
- Documentation: Maintain comprehensive documentation for each feature.
- Access Control: Implement mechanisms to regulate access to sensitive features.
- Versioning Strategy: Develop a clear strategy for feature versioning.
- Automate Updates: Utilize CI/CD pipelines for updating and validating features.
Streamlining ML Workflows with CML IntegrationIntegrating Continuous Machine Learning (CML) is a game-changer for CI/CD in machine learning. It automates critical processes and ensures a more streamlined and efficient workflow.Setting Up CML WorkflowsCreate a GH Actions workflow within your GitHub repository, ensuring it is configured to run on every push or PR.name: model-training
on: [push]
jobs:
run:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install Poetry
run: pipx install poetry
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: "3.10"
cache: "poetry"
- name: Install dependencies
run: poetry install --no-root
- uses: iterative/setup-cml@v2
- name: Train model
run: |
make run
- name: Create CML report
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
echo "\`\`\`" > report.md
cat report.txt >> report.md
echo "\`\`\`" >> report.md
echo "" >> report.md
cml comment create report.md
Conclusion: Boosting Software and AI Ops
In wrapping up, we've delved into the core of DataOps and MLOps, demonstrating their vital role in modern software development, especially in AI. By mastering these practices and tools like DVC and CML, you're learning new techniques and boosting your skillset as a software developer.
- Stay Agile and Scalable: Adopting DataOps and MLOps is essential for developing in the fast-paced world of AI and keeping your projects agile and scalable.
- Leverage Powerful Tools: Mastery of DVC and CML enables you to manage data and models efficiently, making you a more competent and versatile developer.
- Continuous Learning and Application: The journey doesn’t end here. The true potential is realized in continuously applying and refining these practices in your projects.
This is more than just process improvement; it's about enhancing your development workflows to meet the evolving demands of AI and software engineering.
Comment élever l'engagement dans le contexte de travail hybride?

Au mois d'août, Zoom (célèbre pour nous avoir aidés à rester connectés pendant la pandémie) a ironiquement rappelé ses employés au bureau. Vous avez probablement remarqué cette tendance des entreprises à ramener leurs équipes en présentiel. Dans mon réseau, on impose un retour en présentiel 2 à 3 fois par semaine.
Je suis d’accord avec le besoin de créer un environnement de travail engageant où la collaboration règne. Par contre, j’ai de la difficulté avec la décision d'imposer un nombre fixe de jours par semaine. Je crains que les travailleurs qui prospèrent dans des environnements de travail à distance deviennent moins engagés, voire partent tout simplement. On peut se poser la question : le problème d'un engagement plus faible sera-t-il résolu magiquement en ayant les gens de retour au même endroit physique? J'en doute. Après tout, le désengagement et le manque de cohésion dans les équipes existaient avant la pandémie. Je nous encourage à prendre une pause collective pour réfléchir aux solutions qui font du sens.
En parlant à l’équipe chez Osedea, il y a un consensus : l’équipe souhaite que leurs collègues soient plus présents en personne... D’un autre côté, tout le monde apprécie unanimement l'extrême flexibilité que nous offrons.
Dans cet article, je partage mes réflexions et nos apprentissages sur l'évolution des dynamiques de travail, dans l'espoir que cela puisse vous aider dans vos propres réflexions.
Créez des moments mémorables ensemble
Gregg Popoich, l'entraîneur légendaire des San Antonio Spurs, emmène son équipe après chaque match à une excellente expérience culinaire. Les joueurs de la NBA (dont beaucoup sont millionnaires) peuvent se payer toute sorte d’expérience. Mais, comme l'a souligné l'ancien garde des Spurs, Danny Green, dans un article de ESPN en 2020 sur la mentalité de Popovich, « les repas d’équipe nous aident à mieux comprendre chaque personne individuellement, ce qui nous rapproche les uns des autres... et, sur le terrain, à mieux nous comprendre mutuellement. »
En effet, rien ne favorise la cohésion d'équipe comme vivre des expériences mémorables et uniques ensemble. C'était quelque chose que nous faisions très bien au début d'Osedea, lorsque notre équipe était plus petite. Chaque année, nous organisions un voyage tout inclus de cinq jours avec notre équipe. Au menu : formations et cohésion d’équipe. Vous pouvez en savoir plus sur notre voyage à Lisbonne en 2018 ici.
À mesure que nous avons grandi, la logistique de l'organisation de voyages d'équipe réguliers est devenue plus complexe. Il y aussi eu la pandémie. Cette année, nous avons canalisé l'état d'esprit de nos voyages d'équipe et l'avons appliqué au lancement d'OsedeaFest : deux journées pleines d'ateliers inspirants, de délicieux repas et de la découverte de notre ville. Le résultat? Une augmentation de l'engagement et de la connexion de l'équipe, selon nos résultats dans Officevibe et les commentaires de notre équipe.
Organisez vos journées en personne autour de rituels
Il y a certaines activités qui ont plus de sens en personne, tandis que d'autres non. Par exemple, l'été dernier, nous avons repris les entretiens en personne. Cela nous donne l'occasion de créer des liens et de rendre l'expérience du candidat plus mémorable. De même, les démos client sont une excellente occasion de développer des liens et d'offrir une expérience collaborative positive. Chaque fois que nous organisons certains types de rituels, nous nous demandons : est-ce mieux en personne, à distance, ou les deux fonctionnent-ils bien? Nous organisons désormais nos journées en personne autour de cela, plutôt que d'attribuer un nombre arbitraire de jours où les gens doivent être physiquement présents.
Offrez de la flexibilité. Obtenez de la flexibilité en retour.
Notre équipe apprécie la flexibilité que nous offrons. Certains membres de l'équipe, comme moi (quel plaisir de rester quatre minutes à pied du bureau!), viennent au bureau la plupart des jours. D'autres sont réguliers, mais sans jours fixes. D'autres encore sont rarement présents en personne. Cependant, lorsque nous avons une journée d'entretiens, nous n'avons jamais à supplier notre équipe de se présenter ou à négocier leur présence. Nous savons qu'ils respectent le processus, même s'ils sont du type à préférer le travail à distance.
Communiquez différemment pour engager efficacement vos équipes
Un commentaire que j'entends souvent de la part d'autres dirigeants d'entreprise est qu'ils craignent que, s'ils passent entièrement en télétravail, leur équipe sera désengagée de leur entreprise. Si vous pensez qu'être présent en personne pour la communication vous empêchera d'avoir une main-d'œuvre désengagée, je vous invite à réfléchir à nouveau. Nous devons nous remettre en question en tant que leaders, penser différemment et trouver des moyens innovants de communiquer et d'engager l'équipe.
Voici quelques-unes des choses que nous avons faites pour améliorer la communication et l'engagement :
- Impliquez votre équipe en explorant de nouvelles façons de communiquer. Nous avions une infolettre interne qui a duré trois ans avant de commencer à perdre de son impact. Nous avons changé de cap vers un média très engageant : un balado interne. Une fois par semaine, nous diffusons un épisode mettant en vedette différents membres de l'équipe. C'est un excellent moyen de créer une connexion personnelle avec les l’équipe, qui peut l’écouter à sa guise.
- Revoyez les rituels de communication existants. Nous avions organisé notre mise à jour trimestrielle de la même manière (en style de conférence vidéo traditionnelle avec une présentation visuelle) depuis notre création. Pour rendre la présentation de ce contenu important plus dynamique, nous avons changé les choses cet automne avec un format de talk-show virtuel.
Mot de la fin
Selon Indeed, le travail hybride est là pour rester, avec plus de 42 % des emplois affichés dans divers secteurs, y compris des offres de travail hybride. Cependant, le travail hybride peut être bien plus inspirant et gratifiant pour votre équipe qu'une règle monotone imposant un nombre fixe de jours par semaine au bureau. La flexibilité et une approche adaptée à votre équipe peuvent être des différenciateurs plus forts pour attirer des talents et offrir des expériences professionnelles enrichissantes. Alors, avant de sauter dans le train du retour au bureau, je vous encourage à vous poser la question : « pouvons-nous faire mieux? ».
Comment on mène la barque chez Osedea (sans aucun patron)
Osedea a une structure organisationnelle tout à fait unique. Elle s’inspire de l’humanocratie, une approche inventée par Gary Hamel, chercheur à l’Université Harvard, dont l’argumentaire fondé sur les données incite à contourner la bureaucratie, à faire tomber les relations hiérarchiques et à changer l’ADN de l’entreprise pour que tous les membres de l’équipe aient des chances égales de réussir, de grandir et de contribuer.
Pour bien des travailleurs, c’est un concept tout nouveau, alors nous avons pensé vous faire part de nos réflexions et répondre à vos questions sur la réalité des entreprises qui, comme la nôtre, se sont dotées d’une telle structure.
Tout d’abord, qu’est-ce que la bureaucratie?
Nées au 18e siècle, les bureaucraties devaient servir à contrecarrer le népotisme (la pratique qui consiste à nommer des amis ou de la famille à des postes de pouvoir par voie de favoritisme). La bureaucratie devait également encadrer le travail au moyen de règles, de pratiques et de principes qui amèneraient un maximum de gens à se conformer. Plus tard au 20e siècle, le sociologue Max Weber a déclaré que plus la bureaucratie était déshumanisée, plus elle s’approchait de la perfection.
Vous avez probablement déjà travaillé dans une bureaucratie, puisque la vaste majorité des entreprises fonctionnent sur ce modèle :
- La hiérarchie est formelle (approche verticale à niveaux multiples).
- Le pouvoir est relié au poste (certains en ont plus que d’autres, selon leurs fonctions).
- Les supérieurs attribuent les tâches et évaluent le travail.
- Tout le monde compétitionne pour les promotions; la rémunération dépend de l’échelon.
Toutefois, les recherches de Gary Hamel ont révélé des faits troublants sur les bureaucraties :
- 79 % des personnes sondées estimaient que la bureaucratie ralentissait considérablement la prise de décision.
- 68 % disaient que, dans leur entreprise, les nouvelles idées suscitaient le scepticisme ou même l’opposition.
- 76 % trouvaient que les comportements politiques avaient une grosse influence sur l’avancement, au détriment de la compétence ou du potentiel.
Peut-être qu’un environnement hiérarchique traditionnel vous a déjà causé de la frustration? Voici pourquoi les entreprises s’y accrochent malgré tout :
- C’est un moyen bien connu d’inciter les humains à l’action.
- Il est difficile d’imaginer une autre façon de faire.
- C’est efficace jusqu’à un certain point : le travail se fait; il est facile de tout contrôler et coordonner; c’est cohérent.
- Puisque les bureaucraties existent depuis le 18e siècle, des millions de carrières se sont construites autour d’un désir de gravir les échelons et d’atteindre des postes de pouvoir. Or, les humains sont réfractaires au changement.
L’abandon de la bureaucratie habituelle demande du courage, de la créativité et une envie d’avoir une entreprise humaine. En tant que société, nous pouvons y travailler.
De la bureaucratie à l’humanocratie
Osedea est structurée autour des personnes, par opposition à la hiérarchie. Selon nous, les bureaucraties peuvent être déshumanisantes. Elles encouragent les mauvais comportements, les jeux de pouvoir et la politique. Les personnes qui y avancent ne sont pas nécessairement récompensées pour des comportements qui aident l’entreprise. La haute direction a plus tendance à avantager les personnes qui mettent leurs propres intérêts en priorité, qui excellent dans la « gestion ascendante » et qui savent lire les humeurs ou les besoins de leur gestionnaire (plutôt que ceux de l’entreprise) pour mieux y répondre.
Chez Osedea, nous avons opté pour « une structure sans gestionnaires ». C’est un peu différent d’une « structure horizontale », terme fort utilisé – souvent à tort – pour décrire une structure faite de seulement quelques échelons et d’une courte ligne d’autorité. Cette dernière survit difficilement à la croissance et se présente comme un rêve, mais se transforme en un cauchemar logistique et finit en chaos. Si vous voulez en apprendre plus sur les enjeux et avantages d'une structure horizontale, jetez un coup d'oeil à cet article de blogue.
Pourquoi une structure sans gestionnaires?
- Ce type de structure concorde avec notre vision de créer un monde de possibilités pour notre équipe tout en lui rendant la vie belle.
- Elle stimule énormément la créativité, l’apprentissage et l’autonomie.
- C’est une manière de cultiver l’ambition « horizontale » et non l’ambition « verticale », qui correspond au cheminement professionnel habituel, dans le cadre duquel une recrue gravirait les échelons au bout de plusieurs années de service : associé, gestionnaire, vice-président… L’ambition « horizontale » est une structure où les employés qui aiment leur travail sont encouragés à approfondir la chose, à étendre leurs connaissances et à s’améliorer. Cette horizontalité n’annule pas l’évolution. Toutefois, au lieu de récompenser les plus performants par des responsabilités de gestion, qui éloignent souvent les gens de ce qu’ils font réellement de mieux, nous leur offrons des responsabilités proches de leurs fonctions. Nous complétons le tout par des valeurs, des bénéfices et de l’autonomie.
- Tout le monde peut apporter sa pierre à l’édifice chez Osedea, peu importe l’expérience.
- Les résultats sont rapides.
- Les effets négatifs de la bureaucratie disparaissent.
Bien sûr, nous ne disons pas que tout est parfait dans notre structure. Il faut se rappeler que les entreprises évoluent constamment. Nous connaissons notre destination, mais nous rencontrerons des défis. Certains seront faciles à surmonter, d’autres nous suivront longtemps et d’autres encore apparaîtront en cours de route. Il est peut-être difficile d’imaginer comment une organisation peut fonctionner sans structure formelle, mais on se doit d’essayer.
Quelques idées reçues sur notre structure
Pas de gestionnaires, pas de leaders.
Il est important de comprendre que les gestionnaires ne sont pas toujours des leaders. Chez Osedea, nous ne croyons pas au leadership désigné. Le leadership se bâtit plutôt par un travail de qualité supérieure, par une curiosité à l’égard de ce que pourrait faire naître notre vision d’entreprise ainsi que par une influence naturelle sur les autres. Chaque projet a son « chef » ou son équipe initiatrice – qui s’occupe de rassembler les gens autour de la réalisation du projet et qui est la ressource par excellence. Mais nous ne croyons pas en une structure où une seule personne gère les développeurs, les concepteurs, les vendeurs… etc.
Sans gestionnaire, c’est le chaos : impossible de prendre des décisions.
Nous avons des processus efficaces pour tout, des attentes d’équipe et du leadership naturel. On pourrait penser que sans un chef pour statuer, il est impossible d’avancer ou de décider de quelque chose sans que tout le monde s’en mêle. En fait, les personnes qui sont responsables d’un projet, qui le comprennent dans son entièreté et qui connaissent bien le contexte doivent participer à la discussion. Mais au bout du compte, la décision repose sur les informations et les données en main et tient compte de notre vision, de nos valeurs, des parties concernées et des besoins d’entreprise.
Sans gestionnaire, je ne progresse pas dans ma carrière et je ne reçois ni retours, ni mentorat, ni accompagnement.
Nous croyons aux réussites professionnelles. Pour nous, au-delà des postes de direction, tous les chemins mènent au succès. Même si nous n’avons pas de gestionnaires, nous avons des processus et des indicateurs en place qui font en sorte que nos employés atteignent leur plein potentiel, reçoivent des commentaires et sont évalués et encadrés.
Puisqu'il n'y a pas de promotion, rien ne me motive à me dépasser ou à contribuer.
Chez Osedea, le bon travail est récompensé financièrement comme sur le plan des occasions professionnelles (ex. : nous envoyons nos développeurs donner des conférences à l’étranger, même s’ils n’ont pas d’ancienneté; notre développeur Full Stack Robin Kurtz a eu la chance de travailler en tête à tête avec Spot le robot). Nous sommes flexibles, nous pensons différemment, nous encourageons nos gens à s’éloigner des sentiers battus – et des parcours de carrière traditionnels –, et nous dirigeons les membres de l’équipe là où ils sont les plus efficaces et s’épanouissent le plus.
Votre structure est bonne tant que vous avez moins de 100 employés, mais vous n’arriverez pas à la maintenir si vous grossissez.
La croissance est la clé pour toute entreprise, mais si c’est au prix de notre approche d’humanocratie, non merci! Une structure comme la nôtre peut-elle survivre à long terme? OUI! Est-ce qu’il faudra faire des ajustements et des améliorations? OUI. C’est un travail constant. Nous nous accrochons à notre vision, ce qui ne veut pas dire que notre quotidien restera toujours le même.
Aujourd’hui, nous avons des bureaux à Montréal (au Canada) et à Nantes (en France). Bientôt, nous serons au Royaume-Uni. Nos bureaux à l’étranger sont indépendants, mais nous sommes unis par les mêmes missions, valeurs et stratégies. C’est ainsi que nous aurons une croissance à échelle humaine.
Simplification de l'analyse prédictive avec Scikit-Learn
L'analyse prédictive permet aux organisations de prévoir les événements futurs en tirant parti des données passées. Lorsque l'on se lance dans ce travail, surtout d'un point de vue de Minimum Viable Product (MVP), un outil simplifié mais robuste est essentiel, et j'aime commencer avec Scikit-Learn. C'est mon terrain de jeu initial pour l'exploration de l'analyse prédictive.
Aperçu de l'analyse prédictive
Lors d'un récent atelier - "Identifying Opportunities to Leverage AI Within the Manufacturing Sector", nous avons exploré la capacité de l'IA à transformer le domaine manufacturier. Bien que la discussion se soit principalement concentrée sur la fabrication, les connaissances sont applicables à de nombreux secteurs.
Fondamentalement, l'analyse prédictive est un outil agnostique du domaine qui est utile dans tous les domaines, de la santé à la finance en passant par la vente au détail et au-delà.
L'essence de l'analyse prédictive réside dans l'utilisation de données historiques associées à l'IA et à l'apprentissage automatique pour prédire les résultats futurs. Cette prévoyance facilite la prise de décisions stratégiques, minimise les risques et réduit les coûts d'arrêt en signalant les blocages potentiels et les problèmes. Cela nous permet d'optimiser les opérations et de maximiser les profits.
Quelques exemples d'applications :
- Manufacturier: Utilisation de la maintenance prédictive pour réduire les temps d'arrêt des machines.
- Santé: Augmentation du diagnostic précoce et de l'évaluation des risques de maladies.
- FinTech: Renforcement de la détection de la fraude et de l'évaluation du risque de crédit.
Un avantage supplémentaire de l'analyse prédictive réside dans sa transférabilité ; nous pouvons emprunter des stratégies d'un domaine pour apporter de l'innovation à un autre.
Du problème au déploiement du MVP
Passer d'un énoncé de problème à un MVP comprend :
- Un aperçu du problème pour des insights exploitables
- .L'acquisition, le nettoyage, la transformation et la structuration des données.
- La construction et la validation du modèle.
- Le réglage fin des modèles pour les aligner sur le contexte.
Je crois que les personnes, le processus et le produit forment la base de l'innovation technique. Nous pouvons construire de grandes solutions en commençant toujours par une question et une compréhension approfondie du contexte, des récits d'utilisateurs et des parties prenantes.
Scikit-Learn: le MVP
Bien que de nombreux outils et plateformes soient disponibles pour l'analyse prédictive, Scikit-Learn se distingue par sa simplicité, sa facilité d'utilisation et son efficacité, ce qui en fait mon choix préféré pour les MVP et les projets de preuve de concept. C'est une bibliothèque qui abaisse la barrière à l'entrée, rendant l'étape initiale de modélisation prédictive moins intimidante et plus structurée.
Le bénéfice de Scikit-Learn réside dans sa courbe d'apprentissage douce, qui est utile pour les personnes ayant une compréhension fondamentale de Python. Il possède une API bien organisée, cohérente et intuitive qui accélère l'intégration. De plus, il dispose d'une riche bibliothèque d'algorithmes pour diverses tâches d'apprentissage automatique, offrant une plateforme robuste pour construire, expérimenter et itérer sur des modèles prédictifs. La conception modulaire favorise l'extensibilité et l'interopérabilité avec d'autres bibliothèques, renforçant son attrait pour le développement de MVP. La nature simple mais puissante de Scikit-Learn en fait un excellent choix pour le prototypage rapide, accélérant le processus du concept à un modèle fonctionnel, prêt pour une validation réelle.
Dimensions du problème
L'analyse prédictive tourne généralement autour de la classification (catégorisation des données) ou de la régression (prévision de valeurs continues) :
- Classification : Catégorisation des données lorsque la variable de résultat appartient à un ensemble prédéfini (par exemple, 'Oui' ou 'Non').
- Régression : Prévision de valeurs continues lorsque la variable de résultat est réelle ou continue (par exemple, poids ou prix).
Exemple pratique : Analyse de la progression du diabète
Illustrons cela avec un exemple pratique en utilisant un ensemble de données de santé sur la progression du diabète. Grâce à Scikit-Learn, l'accès à un ensemble de données fictives sur le diabète est simple. Cet ensemble de données contient dix variables telles que l'âge, l'IMC et les mesures de sérum sanguin pour plus de 400 patients diabétiques.
Nous cherchons à répondre aux histoires utilisateur suivantes :
- Cadre de santé : Rationalisation de l'admission des patients pour une intervention rapide.
- Médecin : Identification des facteurs contribuant à une prédiction précise de la progression du diabète.
- Patient : Utilisation des mesures de santé pour comprendre et potentiellement atténuer les risques de progression du diabète.
import pandas as pdfrom sklearn import datasets# Load the diabetes datasetdiabetes = datasets.load_diabetes()data = pd.DataFrame(data=diabetes.data, columns=diabetes.feature_names)data["target"] = diabetes.target
Analyse préliminaire et construction du modèle
Avant de se lancer dans la construction du modèle, il est crucial de réaliser une analyse exploratoire. Cela révèle souvent des insights qui guident le choix des modèles prédictifs et des caractéristiques..
import matplotlib.pyplot as pltimport seaborn as sns# Display the first few rows of the datasetdata.head()# Summary statisticsdata.describe()# Correlation matrixplt.figure(figsize=(10, 8))sns.heatmap(data.corr(), annot=True)plt.show()

La matrice de corrélation affiche les relations entre diverses caractéristiques et la variable cible dans l'ensemble de données sur le diabète. Voici les principaux insights de la matrice de corrélation :
Corrélation entre l'IMC et la cible :
- Il y a une corrélation positive entre l'IMC (indice de masse corporelle) et la variable cible, ce qui suggère qu'à mesure que l'IMC augmente, la mesure du diabète a tendance à augmenter également.
Corrélation entre la pression artérielle (bp) et la cible :
- La pression artérielle montre une corrélation positive avec la variable cible. Cela indique que des valeurs de pression artérielle plus élevées sont associées à des mesures de diabète plus élevées.
Negative Correlation of S3 and Target:
- S3 présente une corrélation négative avec la variable cible, indiquant que des valeurs plus élevées de S3 sont associées à des valeurs plus faibles de la mesure du diabète.
Corrélation entre les caractéristiques :
- Les caractéristiques S1 et S2 présentent une corrélation positive élevée, indiquant une forte relation linéaire entre elles.
- S4 et S3 ont une forte corrélation négative, montrant que lorsque une variable augmente, l'autre a tendance à diminuer significativement.
- Les paires S4 et S2 et S4 et S5 présentent également de fortes corrélations positives, suggérant que ces caractéristiques se déplacent probablement ensemble.
Corrélation avec l'âge :
- L'âge présente une corrélation positive avec diverses caractéristiques, notamment la pression artérielle (bp), S5 et S6, et une corrélation positive moins significative mais encore importante avec la variable cible. Ces insights donnent un aperçu de la manière dont diverses variables physiologiques et de test se rapportent les unes aux autres et à la mesure du diabète, ce qui pourrait être crucial pour le développement de modèles prédictifs ou la compréhension des motifs sous-jacents dans l'ensemble de données.
Prétraitement des données
Le prétraitement des données est vital dans la construction d'un modèle d'apprentissage automatique car il prépare les données brutes à être introduites dans le modèle, assurant ainsi de meilleures performances et des prédictions plus précises. Dans ce processus, la standardisation des données et leur séparation en ensembles d'entraînement et de test sont des étapes essentielles.
Le premier objectif ici est d'avoir des ensembles de données séparés pour l'entraînement et l'évaluation du modèle. Une règle générale commune est la règle des 80-20, où 80 % des données sont utilisées pour l'entraînement et les 20 % restants pour le test. Ce ratio offre un bon équilibre, garantissant que le modèle dispose de suffisamment de données pour apprendre tout en ayant encore une quantité substantielle de données non vues pour l'évaluation.
Deuxièmement, la standardisation est cruciale pour de nombreux algorithmes d'apprentissage automatique, en particulier les algorithmes basés sur la distance et les algorithmes basés sur la descente de gradient. Elle met à l'échelle les données pour avoir une moyenne de 0 et un écart type de 1, garantissant ainsi que toutes les caractéristiques contribuent également au calcul des distances ou des gradients.
from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler# Splitting the data into training and testing setsX = data.drop("target", axis=1)y = data["target"]X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42)# Standardize the datascaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
Construction du modèle - Régression linéaire
La régression linéaire est une première étape simple en analyse prédictive en raison de sa simplicité et de sa facilité d'interprétation. Elle fonctionne sous l'apprentissage supervisé, établissant une relation linéaire entre les caractéristiques d'entrée et la variable cible.
from sklearn.linear_model import LinearRegression# Create and train the modellr = LinearRegression()lr.fit(X_train, y_train)
La simplicité de la régression linéaire réside à la fois dans sa commande d'entraînement en une seule ligne et dans sa sortie de modèle, qui est facile à interpréter. Les coefficients nous indiquent le poids ou l'importance de chaque caractéristique, tandis que l'interception nous donne une prédiction de référence lorsque toutes les valeurs des caractéristiques sont nulles. Cette interprétabilité fait de la régression linéaire un excellent point de départ pour la construction de modèles et un outil précieux pour communiquer les résultats aux parties prenantes.
Évaluation et visualisation des résultats
Évaluer les performances d'un modèle consiste à comprendre sa précision et à identifier les domaines d'amélioration. Une métrique standard utilisée dans les tâches de régression est l'erreur quadratique moyenne (MSE), qui quantifie la différence moyenne au carré entre les valeurs réelles et prédites. Une valeur de MSE plus faible indique un meilleur ajustement du modèle aux données, bien qu'il soit important de noter que le MSE est sensible aux valeurs aberrantes.
Visualiser la relation entre les valeurs réelles et prédites éclaire davantage les performances du modèle. Un graphique de dispersion est un outil pratique à cet effet, représentant clairement à quel point les prédictions de notre modèle correspondent aux valeurs réelles. Plus les points se regroupent autour de la ligne d'identité (une ligne avec une pente de 1, passant par l'origine), meilleure est la capacité de notre modèle à faire des prédictions précises.
from sklearn.metrics import mean_squared_errorimport numpy as np# Predictionsy_pred = lr.predict(X_test)# Calculating and displaying the Mean Squared Errormse = mean_squared_error(y_test, y_pred)print(f"Mean Squared Error: {mse}")# Visualizing the actual values and predicted valuesplt.scatter( y_test, y_pred, alpha=0.5) # Added alpha for better visualization if points overlapplt.xlabel("Actual values")plt.ylabel("Predicted values")plt.title("Actual values vs Predicted values")# Adding line of identitylims = [ np.min([plt.xlim(), plt.ylim()]), # min of both axes np.max([plt.xlim(), plt.ylim()]),] # max of both axes# now plot both limits against each otherplt.plot(lims, lims, color="red", linestyle="--")plt.xlim(lims)plt.ylim(lims)plt.show()

Dans cette visualisation, la ligne rouge en pointillés représente la ligne d'identité, où un modèle parfait aurait tous les points. Les écarts par rapport à cette ligne indiquent des erreurs de prédiction. Un tel outil visuel fournit un aperçu qualitatif des performances du modèle. Il sert d'outil d'explication tangible pour les parties prenantes, montrant les forces du modèle et les domaines nécessitant des améliorations dans un format digestible.
Passer à un problème de classification
Notre première approche utilisait un modèle de régression linéaire pour prédire la variable cible continue représentant la progression du diabète. Cependant, comme évalué par l'erreur quadratique moyenne, les performances du modèle ont encore de la marge d'amélioration.
Transformer le problème en un scénario de classification binaire apporte souvent une perspective différente et pourrait conduire à de meilleures performances. Dans certains cas, en le transformant en un problème de classification binaire, nous cherchons à prédire si le diabète d'un patient a progressé en fonction d'un seuil prédéfini.
Définissons la progression comme une variable binaire : 1 si la mesure de progression est supérieure à un certain seuil et 0 sinon. Nous choisirons la médiane de la variable cible dans l'ensemble d'entraînement comme seuil pour la simplicité :
pythonfrom sklearn.preprocessing import Binarizer# Defining the thresholdthreshold = np.median(y_train)# Transforming the target variablebinarizer = Binarizer(threshold=threshold)y_train_class = binarizer.transform(y_train.values.reshape(-1, 1))y_test_class = binarizer.transform(y_test.values.reshape(-1, 1))
Nous pouvons maintenant procéder avec un modèle de classification, maintenant que nous avons notre variable cible binaire. Un choix courant pour de tels problèmes est la régression logistique :
from sklearn.linear_model import LogisticRegression# Training the Logistic Regression modellr_class = LogisticRegression()lr_class.fit(X_train, y_train_class.ravel())# Making predictions on the test sety_pred_class = lr_class.predict(X_test)
Évaluer le modèle
Après l'entraînement, évaluer le modèle sur des données non vues est essentiel pour évaluer ses performances et sa robustesse. Scikit-Learn fournit divers outils, notamment un rapport de classification et une matrice de confusion, qui sont utilisés pour les problèmes de classification. À travers ces métriques, nous pouvons comprendre la précision du modèle, le taux de mauvaise classification et d'autres indicateurs de performance cruciaux.
Rapport de classification
Le rapport de classification fournit les principales métriques suivantes pour chaque classe et leurs moyennes :
- Précision : Le rapport des observations positives correctement prédites au total des prédictions positives. Une précision élevée est liée à un faible taux de faux positifs.
- Rappel (Sensibilité) : Le rapport des observations positives correctement prédites au total des observations dans la classe réelle. Il nous dit quelle proportion de la classe positive réelle a été identifiée correctement.
- F1-Score : La moyenne pondérée de Précision et de Rappel.
- Support : Le nombre d'occurrences réelles de la classe dans l'ensemble de données spécifié.
from sklearn.metrics import classification_report# Evaluating the modelclass_report = classification_report(y_test_class, y_pred_class)print(class_report)
precision recall f1-score support 0.0 0.77 0.82 0.79 49 1.0 0.76 0.70 0.73 40 accuracy 0.76 89 macro avg 0.76 0.76 0.76 89weighted avg 0.76 0.76 0.76 89
Matrice de confusion
Une matrice de confusion est une table utilisée pour évaluer les performances d'un modèle de classification. Elle donne non seulement un aperçu des erreurs commises par un classificateur, mais aussi les types d'erreurs qui se produisent. Dans une matrice de confusion binaire, les éléments diagonaux représentent le nombre de prédictions correctes pour chaque classe, tandis que les éléments hors diagonale représentent les erreurs de classification.
from sklearn.metrics import ConfusionMatrixDisplaydisp = ConfusionMatrixDisplay.from_estimator( lr_class, X_test, y_test_class, display_labels=["Not Progressed", "Progressed"], cmap=plt.cm.Blues,)plt.show()

Dans cette visualisation, chaque colonne de la matrice représente les instances dans une classe prédite, tandis que chaque ligne représente les instances dans une classe réelle. L'étiquette "Non Progressé" est associée à 0 et "Progressé" à 1. Les éléments diagonaux représentent le nombre de points pour lesquels l'étiquette prédite est égale à l'étiquette réelle, tandis que les éléments hors diagonale sont ceux que le modèle classe incorrectement.
Cette matrice colorée représente les performances du classificateur, où les teintes plus foncées représentent des valeurs plus élevées. Ainsi, la diagonale serait nettement plus sombre pour un modèle performant que le reste de la matrice.
Réduction de la Dimensionnalité et Visualisation
n Analyse Prédictive, nos modèles travaillent souvent avec de nombreuses dimensions, chacune représentant une caractéristique de données différente. Cependant, naviguer dans un espace de haute dimensionnalité est délicat et peu intuitif. C'est là que des techniques de réduction de dimensionnalité comme t-SNE (t-Distributed Stochastic Neighbor Embedding) entrent en jeu, agissant comme un pont de la haute dimensionnalité à une représentation visuelle, souvent en 2 dimensions.
Visualiser des données de haute dimensionnalité dans un espace de dimension inférieure, comme 2D, aide à comprendre la distribution des données et les limites de décision du modèle.
from sklearn.manifold import TSNE# Create a TSNE instancetsne = TSNE(n_components=2, random_state=42)# Fit and transform the datatransformed_data = tsne.fit_transform(X_test)# Visualizing the 2D projection with color-codingplt.scatter( transformed_data[:, 0], transformed_data[:, 1], c=np.squeeze(y_test_class), cmap="viridis", alpha=0.7,)plt.xlabel("Dimension 1")plt.ylabel("Dimension 2")plt.title("2D TSNE")plt.colorbar(label="Progressed (1) vs Not Progressed (0)")plt.show()

Le nuage de points coloré produit dans le code ci-dessus montre comment la progression du diabète (catégorisée comme Progressée et Non Progressée) est distribuée dans deux dimensions. Chaque point représente un patient, et la couleur indique le statut de progression. Cette visualisation peut révéler des clusters de points de données similaires, des valeurs aberrantes ou des motifs qui pourraient être corrélés avec les performances du modèle prédictif.
Cette visualisation en 2D pourrait révéler des relations cachées entre les caractéristiques et la variable cible ou entre les caractéristiques elles-mêmes. De telles informations peuvent guider davantage l'ingénierie des caractéristiques, la sélection du modèle ou l'ajustement des hyperparamètres pour améliorer éventuellement la puissance prédictive du modèle.
De telles visualisations peuvent également être un puissant outil de communication lors de la discussion du modèle et des données avec des parties prenantes non techniques. Elle encapsule des relations complexes et de haute dimensionnalité dans une forme simple et interprétable, rendant la conversation sur les décisions du modèle plus accessible.
Récapitulatif
Cette démonstration montre comment passer rapidement d'un problème du monde réel à un simple MVP en utilisant Scikit-Learn pour l'analyse prédictive. Le parcours de la compréhension du problème, du prétraitement des données, de la construction et de l'évaluation des modèles, à la visualisation des résultats est rempli d'apprentissage à chaque étape. Avec des outils simples mais puissants comme Scikit-Learn, l'analyse prédictive est accessible à toutes les parties prenantes.
"
Spot rencontre le premier ministre Justin Trudeau à ALL IN
Nous avons eu l’opportunité de participer à l'événement ALL IN le 27 et 28 septembre 2023, le plus important rassemblement dédié à l'IA au Canada. L'innovation est au cœur de l'économie canadienne et de nos valeurs chez Osedea, et nous avons été inspirés par les idées novatrices des entreprises présentes à cet événement.

Notre célèbre robot Spot a eu l'honneur de rencontrer le Premier Ministre du Canada, Justin Trudeau, qui a même eu l'opportunité de le piloter. Les robots de service, tels que le robot Spot de Boston Dynamics, contribuent à automatiser les tâches répétitives et à faible valeur ajoutée pour l'humain, ce qui représente un atout majeur pour l'économie canadienne. Ils permettront aux entreprises de surmonter les défis liés à la pénurie de main-d'œuvre, d'accroître leur efficacité et de renforcer leur compétitivité sur les marchés mondiaux.



Nous avons également eu l'opportunité de présenter le robot Spot lors d'une conférence de 20 minutes avec Thierry Marcoux et Armand Brière. L'objectif était de démocratiser les robots de services et d'expliquer concrètement l'utilité du robot Spot.

Nous souhaitons remercier Isabelle Turcotte, Patrick Ménard, Louis Deslauriers, M.Sc. , Charlotte BA et toute l'équipe de ALL IN pour cette merveilleuse opportunité. Vous avez fait un travail incroyable, soit l'organisation d'un événement de classe mondiale en IA.
Exploiter les données de votre organisation avec les bases de données vectorielles
Chez Osedea, nous sommes constamment à l'avant-garde des technologies émergentes, et nous avons une perspective unique sur les tendances en matière d'adoption technologique parmi notre base de clients diversifiée. Ces derniers mois, l'IA a fait son entrée dans les médias grand public grâce à ChatGPT. Depuis lors, les outils et le soutien au développement de l'IA ont explosé. Il y a quelques semaines à peine, le Dr Andrew Ng, un leader mondialement reconnu en IA, a prononcé un discours sur les opportunités offertes par l'IA, mettant en évidence l'importance de l'intégration de l'IA dans le flux de travail de votre organisation.
BEARING.ai, la première entreprise à exploiter la puissance de l'IA générative dans l'industrie maritime, est un excellent exemple de la rapidité avec laquelle l'adoption de l'IA peut apporter d'énormes avantages. En utilisant leurs données pour surveiller, prévoir, simuler et optimiser, les clients de BEARING.ai ont réalisé des améliorations substantielles des performances des navires tout en réduisant simultanément les coûts de carburant et les émissions de carbone, contribuant ainsi à un environnement plus vert. Des opportunités similaires ne sont pas des rêves lointains ; elles sont à portée de main. L'IA est prête à être adoptée, et la clé pour en exploiter tout son potentiel réside dans l'utilisation des données de votre organisation.
Les avantages de la centralisation des données
Pour de nombreuses entreprises établies, les données s'accumulent depuis des années dans divers départements et systèmes. Les PDF, les images, les présentations, les e-mails, l'audio, la vidéo et les analyses regorgent d'informations (et sont des actifs importants lorsqu'ils sont exploités correctement). La première étape vers l'adoption de l'IA au sein de votre organisation consiste à centraliser vos données. La centralisation (la consolidation de diverses sources/emplacements dans un seul référentiel ou système) en mettant en place une plateforme de gestion unifiée des données ou en intégrant des systèmes existants grâce à des solutions middleware offre de nombreux avantages :
Base de connaissances alimentée par l'IA : Une fois centralisées, les données peuvent être organisées et indexées de manière efficace grâce à l'aide de modèles d'incorporation. Ces modèles sont formés pour extraire les informations les plus significatives de vos données non structurées. En indexant vos données de cette manière, les grands modèles de langage tels que GPT-4 peuvent étendre leur contexte avec le contexte commercial de votre organisation pour évoluer en un assistant complet et omniscient. Cette approche innovante est connue sous le nom de génération augmentée de récupération (RAG) avec des bases de données vectorielles, un concept que nous aborderons bientôt.
Formation de modèles prédictifs : Le pool de données consolidé devient une ressource précieuse pour la formation de modèles d'IA. Les analyses prédictives, les prévisions et l'analyse des tendances deviennent des objectifs réalisables lorsque vous capitalisez sur les données historiques de votre organisation.
Avantages en matière de sécurité : La centralisation des données offre une infrastructure de sécurité plus robuste pour protéger les informations sensibles. Elle permet un meilleur contrôle d'accès et une meilleure auditabilité, réduisant ainsi le risque de violations de données.
Sauvegardes plus faciles : Les données centralisées sont plus faciles à sauvegarder que les données provenant de sources disparates. Cela simplifie les mesures de protection des données, garantissant que les informations critiques sont préservées en toute sécurité et récupérables en cas de perte de données.
Redondance : La mise en place de la redondance, telle que la mise en miroir ou la réplication des données, devient plus réalisable avec des données centralisées. La redondance améliore la disponibilité des données et la tolérance aux pannes, réduisant les temps d'arrêt et assurant la continuité des activités.
Création d'une base de connaissances alimentée par l'IA
Comme mentionné précédemment, les systèmes de génération augmentée de récupération (RAG) ont pris de l'importance en tant que solution précieuse pour interroger les données d'une organisation à l'aide de grands modèles de langage (LLM). Les systèmes RAG permettent d'interroger les données en langage naturel. Fondamentalement, cela vous permet de "parler" à vos données de la même manière que vous parlez à ChatGPT. L'accessibilité des LLM au cours des derniers mois a rendu cette approche beaucoup plus faisable, c'est pourquoi cette approche de l'exploration des données gagne rapidement du terrain. Cependant, le succès de ces systèmes dépend non seulement des LLM et de l'ingénierie des invites, mais aussi de la vectorisation et de l'indexation correctes des données. C'est là que les bases de données vectorielles et les incorporations jouent un rôle crucial.
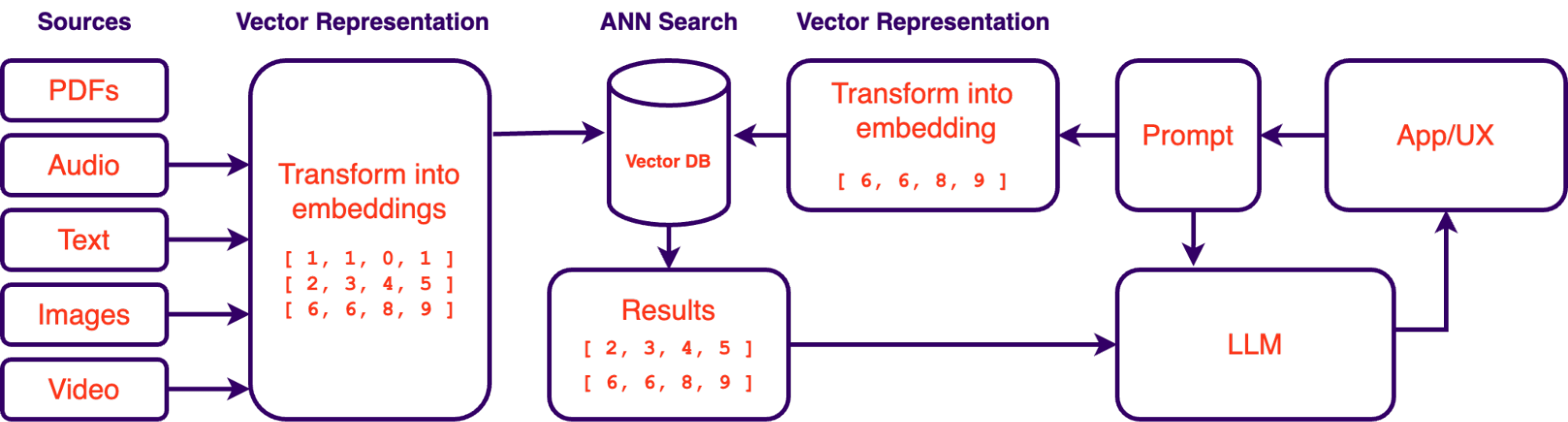
Qu'est-ce que les incorporations vectorielles ?
Dans le contexte de l'IA et de l'apprentissage automatique, les incorporations vectorielles sont une représentation numérique de la sémantique d'une entité. Ces représentations capturent les caractéristiques essentielles et les relations au sein des données, facilitant ainsi le traitement et la compréhension par les algorithmes d'IA. Les incorporations sont essentielles pour des tâches telles que le traitement du langage naturel, les systèmes de recommandation et la reconnaissance d'images. Grâce aux incorporations, nous pouvons rapidement trouver du contenu similaire en fonction de la similitude. De plus, les incorporations ne se limitent pas aux seuls textes, il est possible de créer des vecteurs à partir d'images, d'audio, de vidéos ou de tout type de données en utilisant des modèles d'encodeur formés pour extraire leurs informations significatives. Certains modèles, comme le modèle d'incorporation de texte d'OpenAI-ada-002, sont même agnostiques à la langue, ce qui signifie qu'ils peuvent comprendre la similitude dans diverses langues de manière native.
Qu'est-ce qu'une base de données vectorielle ?
Une base de données vectorielle est une base de données spécialisée conçue pour stocker et récupérer efficacement des incorporations vectorielles en haute dimension, ce qui les rend idéales pour les applications d'IA et d'apprentissage automatique. Elles utilisent des algorithmes de recherche d'approximation du plus proche voisin (ANN) pour mesurer la distance entre les incorporations, ce qui donne une liste classée de vecteurs voisins.
À titre d'exemple, Spotify utilise des bases de données vectorielles depuis un certain temps pour comparer les goûts musicaux des utilisateurs. Ils détaillent également comment ils ont utilisé des incorporations pour interroger leurs épisodes de podcast dans leur article de blog : Présentation de la recherche de langage naturel pour les épisodes de podcast. Ils sont même allés jusqu'à créer leur propre bibliothèque ANN !
Des cas d'utilisation pour les bases de données vectorielles
Les bases de données vectorielles conviennent parfaitement à un large éventail de cas d'utilisation impliquant la recherche de similitudes, les systèmes de recommandation et l'analyse des données dans des domaines tels que l'apprentissage automatique, le traitement du langage naturel, la vision par ordinateur, et bien d'autres. Voici quelques cas d'utilisation courants pour les bases de données vectorielles :
Systèmes de recommandation : Les bases de données vectorielles sont souvent utilisées dans les systèmes de recommandation pour trouver des articles ou du contenu similaire à ce avec quoi un utilisateur a interagi dans le passé. Cela peut s'appliquer au commerce électronique, à la recommandation de contenu, et aux plateformes de musique ou de streaming vidéo.
Recherche basée sur le contenu : Dans les plates-formes de contenu multimédia, les bases de données vectorielles permettent la recherche basée sur le contenu pour les images, l'audio et les fichiers vidéo. Les utilisateurs peuvent rechercher du contenu avec des caractéristiques visuelles ou auditives similaires.
Détection d'anomalies : La détection d'anomalies dans les données de haute dimension, telles que les journaux de trafic réseau, les données de capteurs ou les transactions financières, peut être effectuée à l'aide de bases de données vectorielles. Les points de données inhabituels peuvent être identifiés en les comparant à un ensemble de vecteurs normaux.
Filtrage collaboratif : Les algorithmes de filtrage collaboratif peuvent utiliser des bases de données vectorielles pour trouver des utilisateurs ayant des préférences similaires et recommander des éléments en fonction du comportement d'utilisateurs similaires.
Mémoire à long terme : Les bases de données vectorielles peuvent être utilisées pour stocker les générations de réponses passées d'un LLM. Ces incorporations peuvent être rappelées pour améliorer davantage le contexte d'un modèle de langage avec son contexte passé.
Regroupement : Dans les bases de données vectorielles, le regroupement peut être appliqué pour organiser les données en groupes distincts, facilitant ainsi l'identification de motifs et de similitudes au sein de l'ensemble de données.
Mesure de la diversité : Dans les bases de données vectorielles, la mesure de la diversité peut être appliquée pour évaluer l'étendue et l'inclusivité des recommandations, garantissant une sélection équilibrée d'articles ou de contenu pour répondre à un large éventail de préférences ou de sujets d'utilisateurs.
Les écueils des modèles d'incorporation et des bases de données vectorielles
Bien que les incorporations soient puissantes, elles ne sont pas sans leurs défis. Il est important de connaître les écueils potentiels, tels que les biais dans les données d'entraînement. Par exemple, OpenAI explique dans sa documentation comment un modèle peut associer de manière plus marquée des noms européens américains à un sentiment positif par rapport aux noms africains américains. De plus, les modèles d'incorporation ont des dates de coupure sur leurs données d'entraînement, ce qui signifie que certaines données peuvent varier sémantiquement au fil du temps (par exemple, la popularité d'une célébrité). Le choix des bonnes techniques d'incorporation et des paramètres est essentiel pour obtenir des résultats optimaux, et des techniques appropriées de prétraitement des données doivent être appliquées pour exploiter correctement les incorporations.
Les bases de données vectorielles ne sont que la moitié de la solution
Bien que les bases de données vectorielles et les incorporations soient des composants essentiels de l'adoption de l'IA, il est essentiel de reconnaître qu'ils font partie d'un écosystème plus vaste. La création d'une infrastructure d'IA robuste implique de s'attaquer à d'autres aspects clés tels que le prétraitement des données, la sélection de modèles, l'ingénierie des invites et les stratégies de déploiement. Les bases de données vectorielles sont une pièce puissante du puzzle, mais elles ne sont pas la solution complète.
L'un des problèmes récurrents avec les LLM et l'IA en général est le compromis en termes de précision. Pendant des siècles, les ordinateurs ont été binaires et déterministes. Bien que les bases de données vectorielles puissent représenter une avancée monumentale dans l'exploration des connaissances, elles doivent encore être combinées avec des architectures structurées traditionnelles pour offrir une expérience de recherche ultime. Certaines plateformes, telles qu'Azure Cognitive Search et Elastic Search, travaillent activement à l'amélioration et à l'ajustement des recherches hybrides en utilisant la fusion des classements réciproques (RRF) pour mélanger les classements obtenus. Elastic s'attaque également à d'autres problèmes liés aux bases de données vectorielles, tels que la confidentialité des données et le contrôle d'accès basé sur les rôles (RBAC). Du côté de l'ingénierie des invites, divers cadres tels que guidance ai, Langchain et LMQL sont en cours de développement pour fournir une manière robuste de transformer les données des LLM en réponses structurées significatives. Inutile de dire que nous vivons des moments passionnants, et les architectures RAG émergentes s'améliorent chaque jour.
Chez Osedea, nous reconnaissons le potentiel des bases de données vectorielles, des incorporations et de l'IA pour provoquer des changements transformateurs au sein des organisations. Nos services de développement complets sont conçus pour donner à votre organisation les moyens d'exploiter ses données et de réaliser pleinement le potentiel de l'IA. Que ce soit la centralisation des données, la mise en place de bases de données vectorielles ou la navigation dans les complexités de l'adoption de l'IA, Osedea est là pour être votre partenaire de confiance sur la voie du succès axé sur les données. Soyez assuré que nous restons à l'avant-garde des technologies émergentes et que nous nous engageons à suivre les dernières avancées dans le domaine.
Ce qui rend notre équipe heureuse
Saviez-vous qu’en 2012, les Nations Unies ont instauré le 20 mars comme la Journée internationale du bonheur, mettant en avant son importance universelle et son intégration dans les politiques publiques pour une croissance économique inclusive?
Le bonheur joue un rôle crucial dans notre vie professionnelle, selon des études de l'Université d'Oxford, où un lien direct avec une augmentation de la productivité a été établi. Chez Osedea, nous croyons fermement en l'impact des collaborateurs heureux. Notre culture d'entreprise, ancrée dans la diversité et l'inclusion, vise à créer un environnement où chacun peut s'épanouir. En cherchant constamment à intégrer ces principes pour favoriser le bonheur de nos membres, nous démontrons notre engagement envers leur bien-être, car ils sont notre plus grande richesse.
Initiative Dreams come true
D’abord, nous trouvons important de reconnaître et de soutenir les aspirations individuelles de nos collègues. Ainsi, après deux années de service au sein de notre équipe, nous offrons à chaque membre le privilège de concrétiser un projet personnel grâce à une allocation de 5000$ ainsi qu'une semaine de vacances supplémentaires. Quel genre de projets peuvent-ils entreprendre ? La diversité des choix est infinie, chaque projet étant le reflet des aspirations et des passions uniques de nos collaborateurs. Que ce soit un voyage épique autour du monde, une immersion dans une nouvelle culture, une formation académique pour se perfectionner dans un domaine particulier, ou même la réalisation d'un projet entrepreneurial longtemps rêvé, aucune ambition n'est trop grande ou trop audacieuse. Ce qui rend cette initiative encore plus extraordinaire, c'est qu'elle se renouvelle tous les cinq ans, offrant ainsi à notre équipe la possibilité de continuer à nourrir ses et ses ambitions au fil du temps. Dans cet article, nous partagerons d'ailleurs quelques-unes des inspirantes histoires de réussite de nos collègues, mettant en lumière les rêves devenus réalité grâce à cette initiative unique chez Osedea.
Longs weekends bonifiés
De plus, nous savons à quel point les longs weekends peuvent être revigorants et revitalisants pour le moral et la productivité. C'est pourquoi nous avons pris la décision de prolonger ces moments de repos en ajoutant une journée supplémentaire entre la Journée des Patriotes en mai et le temps des fêtes en décembre. En y réfléchissant bien, cela revient à offrir une semaine de vacances supplémentaire rémunérée au cours de l'année, juste à temps pour profiter des températures douces et ensoleillées. Cette initiative nous permet non seulement de favoriser le bien-être de nos membres, mais elle offre également une opportunité précieuse de décrocher et de se ressourcer. Chez Osedea, nous sommes d’avis qu'un équilibre sain entre le travail et la vie personnelle est essentiel pour le bien-être et la satisfaction au travail, et c'est pourquoi nous nous engageons à offrir des avantages qui favorisent cet équilibre et qui permet de s'épanouir tant sur le plan professionnel que personnel.
Flexibilité du lieu de travail
La flexibilité est un pilier fondamental de notre culture, et elle se reflète dans chacune de nos initiatives visant à promouvoir le bien-être. Cette notion revêt une importance particulière à la lumière des récentes études sur le sujet. Un rapport de l'Organisation internationale du travail de 2023 a révélé que davantage de flexibilité, que ce soit par le biais d'horaires décalés, de partage de postes ou d'options de travail à distance, conduit à une productivité accrue et à un meilleur équilibre entre vie professionnelle et vie personnelle.
Une enquête mondiale menée par Cisco auprès de 28 000 travailleurs à temps plein a montré que 82 % d'entre eux ont déclaré que la possibilité de travailler de n'importe où les rendait plus heureux. De plus, les données de Gallup ont démontré que l'engagement optimal se produit lorsqu'ils passent entre 60 % et 80 % de leur temps de travail en dehors du site de l'entreprise. Ce groupe, qui travaille à distance entre 60 % et 80 % du temps, est également celui le plus susceptible de déclarer avec force que leurs besoins en matière d'engagement liés au développement et aux relations sont satisfaits.
Chez Osedea, nous offrons donc une multitude d'options pour s'adapter aux besoins individuels. Que ce soit en adoptant la semaine de 4 jours, en travaillant depuis n'importe quel endroit dans le monde jusqu'à six semaines, en optant pour le télétravail à temps plein, en travaillant au bureau à 100 % ou en mode hybride, nous encourageons la flexibilité et l'autonomie. Nous sommes convaincus que cette approche permet à nos membres de trouver l'équilibre parfait entre vie professionnelle et vie personnelle, tout en favorisant leur engagement et leur épanouissement au sein de l'entreprise.
Un + pour la famille
Pour de nombreuses personnes, fonder une famille est un objectif essentiel de la vie. Cependant, le chemin vers la parentalité est souvent semé d'obstacles, que ce soit en raison d'infertilité, d'orientation sexuelle ou de contraintes financières. Chez Osedea, nous reconnaissons ces défis et investissons dans des avantages sociaux inclusifs et équitables qui ont un impact réel sur la vie de notre équipe.
Pour soutenir nos collaborateurs dans leur parcours vers la parentalité, quel que soit leur genre ou leur orientation sexuelle, nous avons lancé "Un plus pour la famille". Ce programme novateur, axé sur l'inclusion, comble les lacunes des programmes gouvernementaux, favorise l'égalité et offre un choix, une flexibilité et un soutien adaptés à chaque individu. Nous sommes convaincus que chacun mérite le soutien nécessaire pour fonder une famille, et nous sommes fiers d'offrir ce programme en tant qu'expression de notre engagement envers l'égalité des chances et le bien-être de nos collaborateurs. Pour en savoir plus, consultez cet article.
Chez Osedea, nous plaçons le bonheur et le bien-être de notre équipe au cœur de notre culture d'entreprise. À travers des initiatives innovantes et inclusives, nous créons un environnement où chacun peut s'épanouir pleinement, tant sur le plan professionnel que personnel. Nous sommes convaincus que des collègues heureux sont la clé de notre succès. En restant à l'écoute de leurs besoins, nous continuerons à innover et à améliorer nos avantages sociaux. Nous encourageons notre équipe à partager ses idées pour créer un environnement encore plus dynamique et gratifiant. Ensemble, cultivons un lieu où le bonheur, l'inclusion et l'épanouissement sont essentiels.
Portraits Osedea: à travers voyages, réflexions et ambitions avec Charles Ste-Marie
Plongez dans le monde de Charles Ste-Marie, un individu passionné dont les expériences s'étendent des voyages captivants à travers les continents à la navigation dans le paysage en constante évolution de l'industrie technologique. En tant que membre dévoué de l'équipe d'Osedea, Charles partage ses idées, réflexions et ambitions, offrant un aperçu de son parcours de croissance personnelle et de l'intersection dynamique entre la technologie et la connexion humaine.
Quel voyage t'a le plus marqué?
Trouver le voyage qui m'a le plus marqué est une tâche ardue. Je crois que chaque voyage a sa valeur et apporte quelque chose de différent du précédent (ou du suivant). Je me donne comme objectif personnel de toujours être curieux et ouvert à découvrir de nouveaux pays et de continuer à voyager.
Je reviens tout juste d’un mois au Vietnam. C’était ma première expérience en Asie et j’ai adoré découvrir ce beau pays. Les paysages à couper le souffle, l'histoire riche et la gastronomie locale m'ont captivé. Je recommande à chacun de visiter et d'apprécier la splendeur de la Baie d'Halong ainsi que le chaos harmonieux d'Hanoï.

En 2018, j'ai passé quatre mois en Nouvelle-Zélande, mon tout premier voyage en mode "sac à dos", et j'ai adoré chaque instant de cette expérience. Ayant grandi en écoutant la trilogie du Seigneur des Anneaux, explorer les décors naturels des films et contempler la grandeur de ce pays magnifique restent parmi mes souvenirs de voyage les plus précieux. Il est rare de trouver un endroit où l'on peut gravir une montagne enneigée le matin pour se retrouver les pieds dans le sable à la plage en fin de journée.
Quel aspect de ton travail chez Osedea te passionne le plus et pourquoi ?
Le côté humain de mon travail est ce qui me motive le plus. C’est à travers des discussions autour de nouveaux projets avec des entrepreneurs, dans l’exploration de nouvelles avenues pour une solution technologique désuète avec de belles entreprises québécoises et internationales, ainsi que dans l’échange quotidien avec mes collègues que je connecte avec l’une des valeurs clés d’Osedea : “l’important, c’est d’évoluer ensemble”.
Mon rôle consiste donc à explorer des projets innovants, avec pour objectif ultime de fournir à nos clients une solution technologique de qualité supérieure.
Si tu pouvais changer une chose dans l'industrie technologique, quelle serait-elle et pourquoi ?
Chez Osedea, nous avons la chance de “jaser” et d’explorer une panoplie d'innovations et de nouveautés technologiques, et ce de manière quotidienne. Cependant, je trouve qu’il y a beaucoup de barrières à l'entrée pour quelqu’un n’ayant pas de connaissance technologique poussée, malgré un grand désir d’apprendre. Il est difficile de se retrouver à travers toutes les sphères de la technologie (et encore plus aujourd’hui avec l’essor de l’intelligence artificielle).
Mon conseil pour quelqu’un qui, comme moi, n’a pas nécessairement le background technique, mais a le désir d’apprendre, serait de rester curieux, de poser des questions et d'attaquer quelques formations (J’ai suivi le AWS Cloud Practitioner en 2023 et ce fut une excellente façon d'avoir une meilleure compréhension de l’univers cloud dans son ensemble). Pour les gens plus techniques, tendre la main à ceux ayant le désir d’apprendre et partager votre connaissance est la meilleure façon d’avancer ensemble.
Quelle est la meilleure leçon que tu aies apprise de l'un de tes échecs professionnels ?
Au cours de ma carrière, il y a des moments où j’ai eu l’impression que toutes les bonnes portes se fermaient devant moi, que les opportunités que j’avais tant espérées ou travaillées si fort étaient désormais inaccessibles. Quelques années plus tard, avec un pas de recul, j’ai réalisé que ce n’est pas parce qu’une porte se fermait qu’il fallait arrêter de travailler, au contraire c’est à ce moment que la bonne porte va s’ouvrir.
C’est par ses « échecs professionnels » que j’ai eu la piqûre pour l’univers de la vente et que j’ai commencé à travailler dans de jeunes entreprises/startups (MySmartJourney et MonClubSportif), où j’ai énormément appris et perfectionné mes compétences. Ces deux emplois et les apprentissages qui en découlent m’ont permis de faire le saut chez Osedea il y a un peu moins de deux ans.
Quel est ton meilleur souvenir de travail chez Osedea jusqu'à présent ?
L’OsedeaFest organisé à l’automne 2023 est sans aucun doute l’un de mes meilleurs souvenirs chez Osedea. Ce festival de deux jours organisé par notre équipe activité a été un franc succès pour rassembler tout le monde, nous rapprocher et créer de beaux souvenirs en équipe. Lors de la dernière journée, une Amazing Race a été organisée dans le quartier Saint-Henri, où le bureau d’Osedea est situé. Pendant près de 4 heures, nous étions divisés en équipes de 4 à 5 personnes et avions à accomplir une panoplie de défis. J'ai déjà hâte à l’édition 2024 !

Dans une optique plus “travail”, mon séjour d’un mois en France pour Osedea fut une opportunité en or. Combiner l’international à mon travail a toujours été un objectif personnel et professionnel.
Quelle est la dernière compétence que tu as développée et comment cela a-t-il amélioré ton travail ?
Au cours des derniers mois, j’ai décidé de me former davantage sur nos différentes expertises chez Osedea. J’ai eu l’opportunité de travailler plus sur le robot Spot de Boston Dynamics, je me suis donc donné comme mission d’avoir une meilleure compréhension des différents cas d’usage de Spot et de mieux comprendre ses payloads (équipements pouvant être mis sur le robot, comme une caméra thermique, un lidar, etc.).
Concrètement, la dernière formation que j'ai suivie chez Osedea est "Introduction to Generative AI" offerte par Google Cloud. Avec l’essor de l’IA et du Generative AI, je voulais avoir une meilleure compréhension du Generative AI dans son ensemble et des différents services offerts par Google Cloud. De manière plus informelle, j’aime bien prendre le temps de discuter avec mes collègues plus techniques pour avoir une meilleure compréhension de nos projets.
Quel est ton endroit préféré pour trouver l'inspiration ?
J’ai toujours adoré travailler dans des cafés ! Étant 100% en télétravail de Québec, sortir de chez moi et m’installer dans l’un de mes cafés préférés me permet vraiment d’être productif et d’avancer ma to do list.
Ayant plusieurs rencontres virtuelles chaque jour, me bloquer un moment focus dans un café me permet de travailler sans interruption. C’est une façon d’optimiser ma productivité que j’ai toujours valorisée, que ce soit durant mes études et maintenant dans mon quotidien chez Osedea. Étant un grand fan de café, ça me permet de joindre l’utile à l’agréable.
Quelle est ta plus grande ambition professionnelle pour l'avenir ?
’aimerais potentiellement enseigner ou redonner d’une quelconque façon. Ayant longtemps été entraîneur de hockey et plus récemment l’un des coordonnateurs du programme de Missions Commerciales de l’Université Laval, j’ai réalisé que j’avais beaucoup de plaisir et d’intérêt à partager mes connaissances et à voir l’amélioration chez les jeunes hockeyeurs ou les étudiants. Dans un monde idéal, je trouverais une façon de mêler mes intérêts pour l’enseignement, l’international et les technologies dans un rôle. Je ne suis pas pressé d’atteindre cet objectif, pour l’instant j’ai le désir d’être sur le terrain et d’apprendre tous les jours, que ce soit par des formations, par des expériences professionnelles ou par mes collègues autour de moi.
Quelle est la chose la plus excitante à propos de l'avenir de l'industrie technologique selon toi ?
L’industrie technologique est en perpétuelle évolution et l’avenir est difficile à prédire. À mes yeux, c’est ce qui est le plus excitant dans cet écosystème technologique, que les idées innovantes grandissent partout autour de nous et qu'elles sont de plus en plus accessibles (Intelligence artificielle, IoT, Réalité augmentée et virtuelle, robotique, etc.). Chez Osedea, nous nous donnons comme mission d’être à l'avant-garde des tendances et de tester ces innovations. Au Québec, j’ai hâte de voir la croissance de notre écosystème technologique. Au cours des dernières années, je sens qu’il y a un désir d’innover, de se démarquer et de continuer de bâtir un écosystème technologique encourageant pour la jeune entreprise (Startup, PME), ainsi que la moyenne/grande entreprise qui désire optimiser ses processus technologiques. Si j’avais une prédiction à faire pour les prochaines années, j’ai l’impression que nous allons assister à l’explosion des innovations quantiques, à la croissance de l'écosystème autour de la filière batterie et à une continuation des projets/investissements en IA.
Si tu pouvais échanger de place avec un membre d'une équipe différente chez Osedea pendant une semaine, le ferais-tu et pourquoi ?
Ça ne m’a jamais traversé l’esprit de changer de rôle chez Osedea. Ce qui m’a immédiatement plu dans notre approche des ventes chez Osedea, c’est que la priorité va toujours être d’amener des projets excitants à notre équipe. Pour répondre à ces attentes, on se doit de travailler en étroite collaboration avec nos collègues de tous nos départements pour qualifier, filtrer et sélectionner les meilleurs projets. Je me sens chanceux de pouvoir échanger avec mes collègues en IA et en ingénierie logicielle pour un projet X, tandis que la conversation suivante va être axée sur la conception d’une nouvelle solution. Si on m’obligeait, je me convertirais en développeur sur notre robot Spot. Je trouve que c’est extrêmement concret comme cas d’usage et qu'il y a un côté « terrain » que j’apprécie beaucoup.
Exploiter le « chain-of-thought » pour une communication efficace dans différents modèles de language de programmation
Il y a un peu plus d'un mois, nous avons organisé notre premier hackathon sur l'IA chez Osedea. Depuis l'événement, nous sommes en quête de dévoiler tout le potentiel de Chat GPT et de l'IA générative. En constatant les capacités de ce vaste modèle linguistique lors du hackathon, nous sommes devenus obsédés par la maîtrise de sa puissance pour fournir les résultats les plus précis et éclairants. Cela nous a entraînés dans le terrain du « Prompt Engineering ».
Cet article partagera certaines des connaissances que nous avons acquises lors de notre Hackathon et notre perspective pour l'avenir. Ainsi, vous pourrez trouver des informations faciles à comprendre et à assimiler sur le sujet en un seul endroit.
Avec la montée en popularité de ChatGPT, l'IA générative gagne en importance en tant que concept prometteur dans le domaine de l'intelligence artificielle, notamment dans le traitement du langage naturel. Cette approche vise à aligner le comportement de l'IA sur l'intention humaine. Les ingénieurs d'incitation «prompt engineers» construisent soigneusement des incitations pour pousser les modèles d'IA générative à leurs limites, ce qui se traduit par une amélioration des performances et de meilleurs résultats pour les outils d'IA générative existants. Avant d'entrer dans certaines des techniques de l'ingénierie d'incitation, permettez-nous de donner d'abord un bref aperçu du fonctionnement des grands modèles de langage (GML).
Alors, comment les modèles de langage fonctionnent-ils réellement?
Les modèles de langage (ML), y compris les grands modèles de langage (GML) qui alimentent des chatbots comme ChatGPT, sont des modèles probabilistes conçus pour identifier et apprendre les schémas statistiques dans le langage naturel. Au cœur de ces ML, on calcule la probabilité qu'un mot apparaisse à la fin d'une phrase donnée en entrée. Ces modèles sont utilisés depuis un certain temps déjà, même dans des applications quotidiennes comme la prédiction de texte sur les smartphones, où des suggestions pour les prochains mots sont fournies en fonction de l'entrée.
La principale distinction entre les ML et les GML réside dans la taille du modèle. Avec les avancées récentes dans les architectures d'apprentissage automatique et l'entraînement distribué, les développeurs peuvent désormais entraîner des GML à une échelle beaucoup plus grande. Cette augmentation de la taille améliore la précision statistique du modèle. (Bien que cela soit une simplification du fonctionnement des GML, il est important de noter qu'il y a d'autres facteurs en jeu, tels que le réglage fin et l'apprentissage par renforcement).

Absence de raisonnement dans les GML
Bien que les GML excellent dans la prédiction, il est essentiel de comprendre qu'ils ne possèdent pas une véritable intelligence ni des capacités de raisonnement. Les GML sont essentiellement de grandes machines à prédiction et ils sont dépourvus de la capacité de penser ou de raisonner derrière leurs résultats. Par exemple, si je lui demandais de générer une phrase se terminant par le même mot avec lequel elle a commencé, un GML comme GPT-3 aurait du mal à répondre à cette demande.

L'exemple ci-dessus démontre que les GML, y compris ChatGPT, s'appuient fortement sur les schémas statistiques qu'ils ont appris et manquent d'une véritable compréhension ou d'un raisonnement.
Hallucinations
Ce que nous voyons dans la réponse exemple ci-dessus est également connu sous le nom d'hallucination. Les hallucinations font référence à des réponses confiantes générées par un modèle qui ne sont pas étayées par ses données d'entraînement. Aussi appelées confabulation ou délire, ces hallucinations surviennent lorsque qu'un algorithme classe une réponse avec une grande confiance, même si elle est sans rapport ou incorrecte. Ce phénomène découle des limitations du GML et n'est pas contextualisé comme une faiblesse du modèle. Les hallucinations mettent en évidence l'importance de la prudence lors de la dépendance envers les modèles d'IA pour des réponses factuelles nécessitant du raisonnement, car elles peuvent fournir des informations trompeuses ou inexactes.
Capacités émergentes
Dans l'exemple ci-dessus, on a posé la même question à GPT-4, mais cette fois-ci, il a répondu correctement à l'incitation contrairement à GPT-3. Les capacités émergentes sont un phénomène intrigant observé dans les Grands Modèles de Langage (GML), alors qu'ils grandissent en taille et en complexité. Les chercheurs ont remarqué que lorsque les GML, comme GPT-4, sont entraînés sur de plus grandes quantités de données avec plus de paramètres, ils commencent à manifester de nouveaux comportements qui vont au-delà de leurs capacités attendues. Le développement de nouvelles capacités peut être comparé au déblocage de super pouvoirs, tels que la traduction, la programmation, voire même la compréhension des blagues.
C'est à la fois fascinant et quelque peu préoccupant, car ces capacités émergentes ne sont pas explicitement programmées dans les modèles, mais émergent plutôt grâce au processus d'apprentissage à partir de vastes quantités de données textuelles. L'article d'OpenAI sur GPT-4, intitulé "Étincelles d'AGI", explore les détails de ces nouvelles capacités et les signes d'intelligence générale qu'elles présentent. Cependant, malgré ces capacités émergentes, le défi fondamental du raisonnement dans les GML persiste toujours. À mesure que nous continuons à développer des modèles de langage, nous pouvons nous attendre à ce que des effets et des capacités plus inattendus émergent, façonnant le paysage de l'IA de manière passionnante et imprévisible.
Maintenant que nous avons compris les bases des GML, penchons-nous sur l'ingénierie d'incitation.
Qu'est-ce que le « prompt engineering »?
Le « prompt engineering » est une discipline émergente qui se concentre sur le développement et l'optimisation d'incitations pour une utilisation efficace des modèles de langage (ML). Il constitue une approche cruciale pour comprendre les capacités et les limites des grands modèles de langage et améliorer leur performance dans diverses tâches, telles que la réponse à des questions et le raisonnement arithmétique. Grâce au « prompt engineering », les chercheurs et les développeurs utilisent diverses techniques pour concevoir des incitations efficaces et robustes qui interagissent avec les GML et d'autres outils.
Cette discipline joue un rôle essentiel dans l'expansion de la capacité et de l'applicabilité des GML dans diverses applications et sujets de recherche. Certaines techniques d'incitation notables comprennent l'incitation à zéro-shot, l'incitation à quelques tirs, l'incitation en chaîne de pensée, l'auto-consistance, l'incitation à générer des connaissances, l'ingénieur d'incitation automatique, l'incitation active, l'incitation à stimulus directionnel, l'incitation ReAct, l'incitation multimodale en chaîne de pensée, l'incitation arborescente de pensées et l'incitation graphique. À mesure que le « prompt engineering » continue d'évoluer, de nouvelles techniques sont régulièrement développées, témoignant des efforts continus dans ce domaine. Passons en revue quelques-unes de ces techniques en détail.
« Zero-shot prompting »
Le « zero-shot prompting » est une technique simple dans le cadre du « prompt engineering » qui exploite les capacités inhérentes des GML. Avec le « zero-shot prompting », il est possible d'obtenir des résultats précis sans fournir explicitement des instructions détaillées. Par exemple, lorsqu'on lui demande une analyse de sentiment sans définir explicitement ce qu'est le sentiment, GPT démontre sa compréhension en générant une réponse précise pour l'analyse de sentiment. Cela met en évidence la capacité de GPT à répondre correctement d'emblée en se basant sur sa compréhension intégrée du sentiment.
« Few-shot prompting »
Le « few-shot prompting » pousse l'ingénierie d'incitation un peu plus loin en incorporant des résultats d'exemples aux côtés de l'incitation. Cette approche permet un apprentissage en contexte et guide le modèle vers une meilleure performance. Dans l'exemple fourni, nous observons une approche à un seul exemple où le modèle apprend à effectuer la tâche en se basant sur un seul exemple. Cependant, nous pouvons améliorer l'incitation en l'enrichissant avec plus d'exemples, ce qui conduit à des réponses plus précises du modèle. En ajustant l'incitation et en utilisant ces techniques, nous pouvons clairement observer les effets sur la sortie désirée. Il est à noter que pour des tâches plus complexes, augmenter le nombre de démonstrations, comme 3 exemples, 5 exemples, 10 exemples, etc., peut être expérimenté pour améliorer davantage la performance du modèle.

« Chain-of-thought prompting » (CoT)
Le « Chain-of-thought prompting » est une technique utilisée pour améliorer les capacités de raisonnement des grands modèles de langage (GML). L'idée derrière cette approche est de guider les GML en leur montrant les étapes impliquées dans la résolution d'un problème spécifique, similaire à l'enseignement à un jeune enfant comment faire des mathématiques. Au lieu d'attendre des réponses directes, les GML voient le processus pour arriver à la solution. En fournissant une chaîne de pensée comme exemple, les GML apprennent à générer leur propre processus de raisonnement, ce qui conduit à des sorties plus précises.

En 2022, des chercheurs de Google ont publié un article sur le chain-of-thought prompting, mettant en évidence son impact sur les résultats d'incitation. Ils ont mené des expériences en utilisant des références pour les capacités de raisonnement arithmétique dans les GML et ont observé des améliorations significatives lors de l'utilisation du chain-of-thought prompting. Les résultats ont montré des scores plus élevés pour les tâches de raisonnement par rapport aux méthodes d'incitation standard. Il a également été noté que le chain-of-thought prompting est une capacité émergente dans les grands modèles de langage, ce qui indique la nature évolutive des techniques d'incitation et leur dépendance à la taille du modèle.

Auto-consistance avec le « chain-of-thought »
Bien que le « chain-of-thought » ait démontré des résultats positifs, il n'est pas sans limites. Certaines tâches peuvent encore poser des défis aux GML, et des améliorations supplémentaires sont nécessaires pour améliorer leurs performances. Cependant, les gains empiriques obtenus grâce au « chain-of-thought » prompting ont mis en évidence son potentiel pour améliorer les capacités de raisonnement des GML, surpassant même les modèles fins. À mesure que le domaine de l'ingénierie d'incitation continue d'évoluer, on s'attend à ce que de nouvelles approches et techniques affinent davantage les capacités des modèles de langage à l'avenir.

En plus du « CoT », nous pouvons ajouter une technique appelée auto-consistance qui fait référence à une méthode consistant à créer une moyenne des résultats obtenus à partir de plusieurs itérations d'une incitation en chaîne de pensée. Contrairement aux autres techniques mentionnées précédemment, cette approche ne se concentre pas sur l'incitation elle-même, mais plutôt sur la génération de réponses diverses en répétant la même incitation en chaîne de pensée à un seul exemple plusieurs fois.
ans l'exemple ci-dessus, en examinant la réponse la plus cohérente parmi les trois itérations, vous pouvez arriver à un résultat valide, qui dans ce cas est 9.
« Tree-of-thought »
Une technique récemment apparue appelée le « Tree of Thoughts»a gagné en importance dans l'auto-consistance avec le « chain-of-thought ». Le ToT aborde les limites des modèles de langage dans les tâches de résolution de problèmes. Étant donné que les modèles prennent des décisions en se basant sur des jetons individuels de manière de gauche à droite, cela restreint leur efficacité dans les tâches impliquant l'exploration et la planification stratégique.

Pour surmonter ces limitations, le cadre ToT étend l'approche du « Chain of Thought ». Il permet aux modèles de langage de considérer des unités cohérentes de texte appelées « pensées » comme des étapes intermédiaires dans la résolution de problèmes. Avec ToT, les modèles peuvent prendre des décisions délibérées en explorant différents chemins de raisonnement, en évaluant des choix et en déterminant la meilleure démarche à suivre. Ils peuvent également anticiper ou revenir en arrière au besoin pour prendre des décisions plus éclairées.
ReAct (Raisonner + Agir)
Et enfin, nous avons ReAct, qui signifie « Raisonner et Agir ». C'est une technique populaire qui exploite les modèles de langage pour générer à la fois des traces de raisonnement et des actions spécifiques à la tâche. Elle permet aux GML de non seulement fournir leurs réflexions et leurs idées, mais aussi d'effectuer des actions qui interagissent avec des sources externes telles que des bases de données, des environnements ou des API.
Avec ReAct, les GML ont accès à des outils tels que des navigateurs Web avec Puppeteer, des systèmes de fichiers ou toute API souhaitée. Cet accès leur permet d'utiliser des ressources externes pour des tâches telles que la recherche Web ou la récupération d'informations à partir de bases de connaissances. Les traces de raisonnement générées aident les GML à induire, suivre et mettre à jour des plans d'action tout en gérant les exceptions.
En incorporant des outils externes et en générant des actions spécifiques à la tâche, ReAct améliore la compréhension des GML de la tâche en cours et facilite la récupération d'informations précises et fiables.
Que pouvons-nous faire avec le « prompt engineering » ?
Êtes-vous enthousiaste? Maintenant que nous avons appris ces techniques de « prompt engineering » fascinantes, explorons comment nous pouvons en tirer le meilleur parti. La bonne nouvelle, c'est que vous n'avez pas besoin de devenir un expert dans ces techniques. Comprendre les bases est suffisant, car il existe des outils puissants disponibles qui mettent en œuvre ces techniques de manière transparente. L'un des principaux cadres de travail dans le domaine du « prompt engineering » est appelé Langchain.

Langchain, un cadre Python et TypeScript lancé en octobre dernier, fournit tous les éléments essentiels pour exploiter efficacement les capacités des grands modèles de langage. Langchain s'intègre à un large éventail de principaux fournisseurs de modèles, dont OpenAI, HuggingFace, Google et d'autres. Ces intégrations sont incroyablement pratiques car elles permettent de facilement échanger des modèles de langage, vous permettant ainsi de tester différents comportements auprès de divers fournisseurs. De plus, Langchain offre un support pour une liste étendue d'outils avec lesquels les agents peuvent interagir. Des moteurs de recherche aux fonctions AWS Lambda et Twilio, vous pouvez également intégrer vos propres outils et modèles en toute simplicité en utilisant la même interface.
Le cadre propose également une variété d'agents d'outils prêts à l'emploi, répondant à différentes finalités. Par exemple, les agents SQL et JSON gèrent les données structurées de manière indépendante, permettant à plusieurs agents d'interagir entre eux de manière transparente.
Langchain est divisé en sept modules : modèles, incitations, mémoire, index, chaîne, agents et rappels. En tirant parti de ces modules, vous pouvez rapidement construire des applications puissantes. Par exemple, avec seulement quelques lignes de code, vous pouvez créer un outil qui consomme des PDF et résume leur contenu. Langchain vous permet de construire des applications personnalisées, sans être limité à un modèle de langage spécifique comme GPT-4.
Mot de la fin
Alors que nous concluons notre exploration de l'ingénierie d'incitation et de son rôle dans l'avancement des modèles de langage, nous sommes rappelés de la nature en constante évolution du paysage de l'IA. Chez Osedea, nous nous engageons à rester à la pointe de ce domaine dynamique, et nous favorisons activement un environnement d'apprentissage continu, de collaboration et d'innovation.
Que ce soit en organisant des hackathons IA, en animant des ateliers ou en participant régulièrement à des discussions autour de l'IA, ces initiatives servent d'opportunités pour notre équipe et d'autres personnes partageant les mêmes idées de se réunir, de se mettre au défi et d'échanger des idées. En participant activement à ces activités, nous améliorons non seulement nos propres capacités, mais contribuons également à la croissance collective et au développement de l'IA.
Dans cet environnement en constante évolution, la collaboration, le partage des connaissances et l'apprentissage continu sont essentiels. En favorisant un environnement qui encourage l'exploration et l'innovation, nous pouvons collectivement naviguer dans le paysage de l'IA en évolution et débloquer de nouvelles frontières de possibilité.
Alors que nous anticipons des avancées significatives dans les technologies de l'IA dans les mois et les années à venir, il est important de rester adaptables. La disponibilité des outils et des cadres aujourd'hui témoigne du potentiel et des possibilités qui nous attendent. Embrassons la nature dynamique de l'IA et soyons prêts à exploiter les avancées qui façonneront notre avenir.
Crédit photo : Mojahid Mottakin