Développement
Nettoyage des données avec Python Pandas

Les projets d'apprentissage (« machine learning ») automatique et d'apprentissage en profondeur (« deep learning ») gagnent en importance pour de nombreuses organisations. Le processus complet comprend la préparation des données, la création d'un modèle analytique et son déploiement en production.
Il existe différentes techniques pour préparer les données, y compris le traitement par lots d'extraction-transformation-chargement (ETL), la gestion de flux et de données, etc. Mais comment pouvez-vous tout trier?
Dans cet article, nous allons faire un survol du nettoyage des données et comment travailler avec des données à l'aide de Python Pandas.
À la fin de ce guide, nous vous présenterons une démonstration détaillée du nettoyage des données avec Pandas dans un projet ETL réel.
Vous voulez accéder au code source final de ce que nous allons créer !

Un bref aperçu
À quoi consiste le nettoyage des données?
Le nettoyage des données est le processus de préparation des données pour l'analyse. Celui-ci consiste à supprimer ou corriger les données incorrectes, incomplètes, non pertinentes ou dupliquées dans un ensemble de données. C'est l'une des étapes essentielles de l'apprentissage automatique puisqu’elle joue un rôle clé dans la construction d'un modèle.
En quoi est-ce important? Nourrir de mauvaises données dans n'importe quel système n’est jamais une option. Une mauvaise qualité des données conduit à de mauvais résultats : « Garbage In, Garbage Out ».

Le nettoyage des données peut sembler être une tâche fastidieuse, mais c'est un élément fondamental pour la résolution de tout problème d'analyse de données. De bonnes peuvent être utilisées pour produire des informations précises et fiables. Les data scientists/ingénieurs passent 60 à 80 % de leur temps à effectuer des nettoyage de données.
Comment nettoyer les données?
Le nettoyage des données donne aux données la bonne forme et la qualité requise pour l'analyse. Il comprend de nombreuses étapes différentes, par exemple :
- bases (sélectionner, filtrer, supprimer les doublons, …)
- L'échantillonnage (équilibré, stratifié, …)
- Le partitionnement des données (créer l'apprentissage + la validation + le jeu de données de test, …)
- Les transformations (normalisation, standardisation, mise à l'échelle , pivotement, …)
- Binning (basé sur le nombre, gestion des valeurs manquantes comme son propre groupe, …)
- Remplacement de données (découpage, fractionnement, fusion, …)
- Pondération et sélection (pondération des attributs, optimisation automatique, …)
- Génération d'attributs (génération d'ID , …)
- Imputation (remplacement des observations manquantes en utilisant des algorithmes statistiques)
Maintenant que nous sommes sur la même page de ce qu'est le nettoyage des données et de son importance, nous allons explorer quelques aspects pratiques d'un nettoyage efficace des données avec Pandas !
Nettoyage des données avec Pandas
Qu'est-ce que Pandas?
- Pandas est l’une des librairies de Python qui vous donne un ensemble d'outils pour faire du traitement de données.
- Elle a d'excellentes performances car elle est construite sur Numpy, qui est écrit en C, donc Pandas s'exécute rapidement.
- Que pouvons-nous faire avec les données en utilisant Pandas ? Avec Pandas, nous pouvons effectuer du remplissage de données, de la normalisation de données, des fusions et des jointures, des analyses statistiques et bien plus encore…
Comment faire?
Jetons un coup d'œil à certaines commandes Pandas qui seront fréquemment utilisées :
(Notebook pour le contenu suivant)
1. Créer un DataFrame
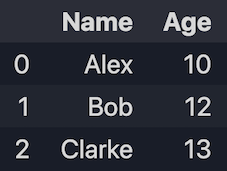
1.1 Créer à partir de listes
import pandas as pd
data = [['Alex', 10], ['Bob', 12], ['Clarke', 13]]
df = pd.DataFrame(data, columns=['Name', 'Age'])
print(df)
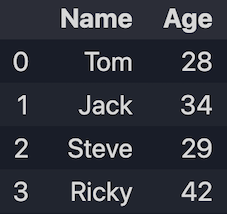
1.2 Créer à partir des dicts
data = {'Name': ['Tom', 'Jack', 'Steve', 'Ricky'], 'Age':[28, 34, 29, 42]}
df = pd.DataFrame(data)
print(df)
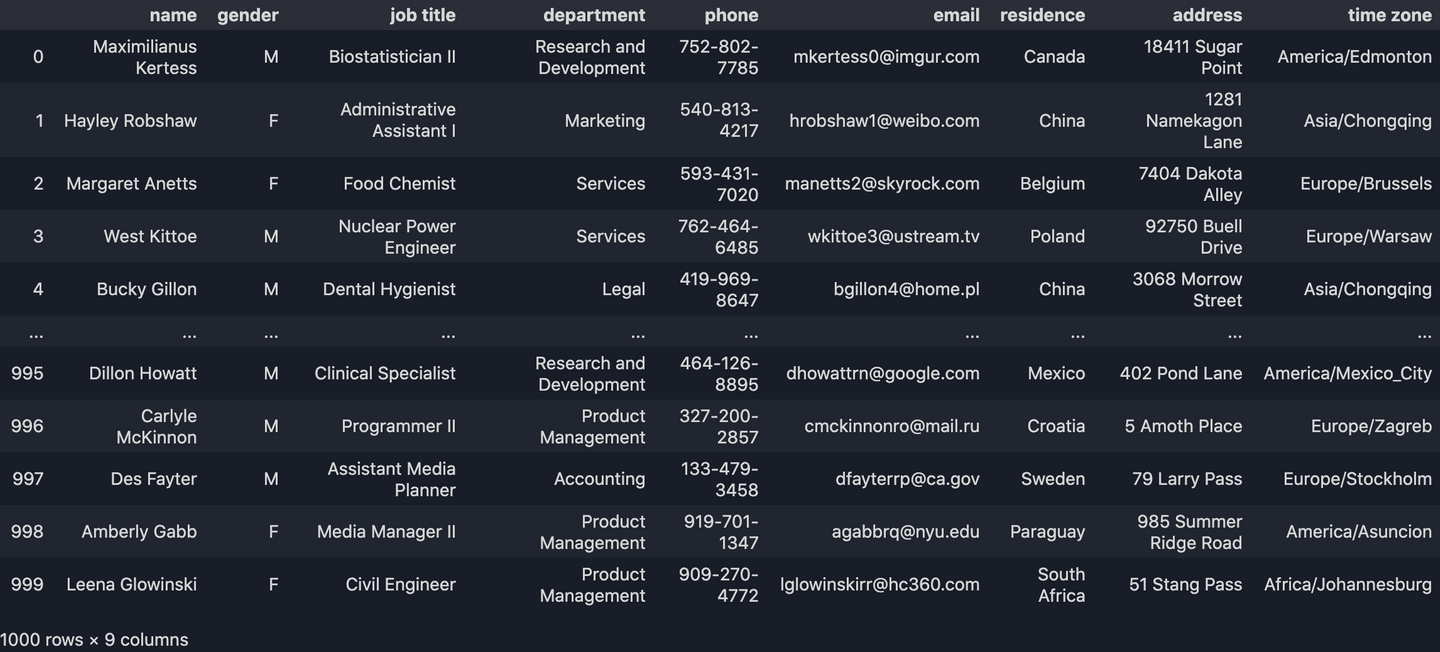
2. Importer un jeu de données
(Les exemples suivants utilisent ce jeu de données)
df = pd.read_csv("data.csv")
print(df)
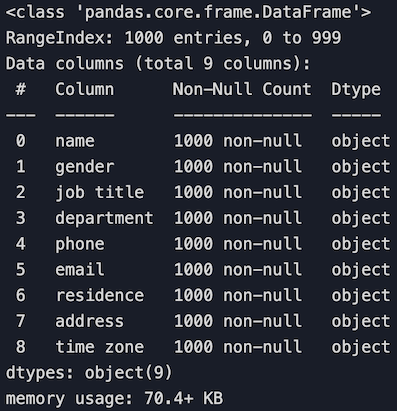
3. Obtenir une information générale sur un jeu de données
df.info()
4. Sélection d'une ligne/colonne
4.1 Sélectionnez une colonne
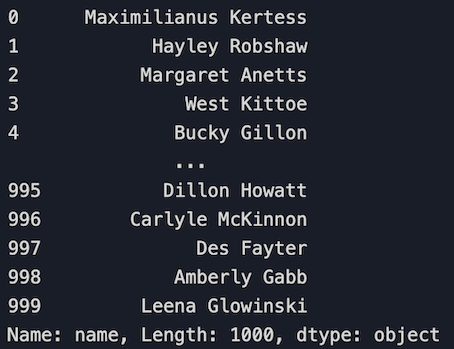
# Select the 'name' column
df['name']
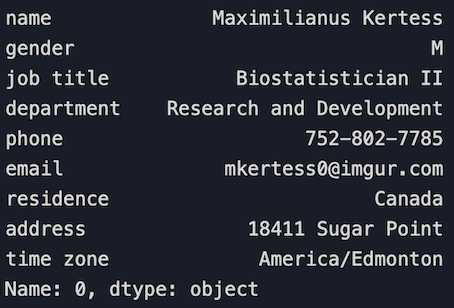
4.2 Sélectionnez une rangée
# Sélectionnez la première ligne
df.loc[0]
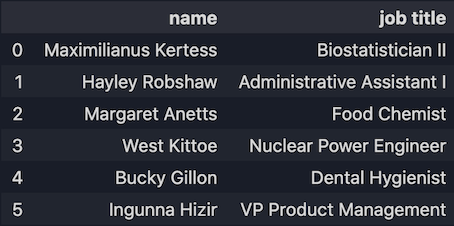
4.3 Sélectionnez plusieurs lignes et colonnes à l'aide de loc[]. Celui-ci peut prendre deux entrées :
loc[<rows_to_select>,<columns_to_select>]
Obtenir les informations de la ligne 0 à 5 et avec les colonnes 'name' et 'job title'.
df.loc[0:5,["name","job title"]]
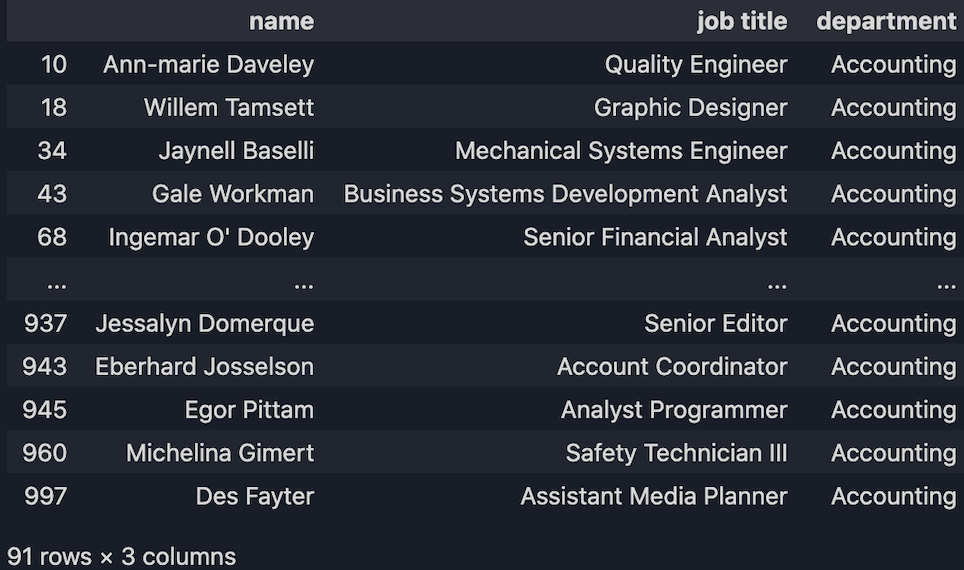
Obtenir les informations en fonction de certaines conditions. Par exemple, nous voulons obtenir tous les employés qui travaillent au service Comptabilité :
df.loc[(df["department"] == "Accounting"), ["name", "job title", "department"]]
Et bien plus…
# Delete a column
del df['column_name']
df.drop('column_name', axis=1)
pop('column_name')
# Drop duplicates
df.drop_duplicates()
# Data filling
df['column_name'].fillna('some_values')
# Sorting
df.sort_values(by='column_name')
# Merge
df.merge(data_2, on='column_name', how='left')
# Query
df['column_name'].where(df['column_name'] > 50)
# Check data types
df.dtypes
df.dtypes['column_name']
Consultez la documentation pour plus de fonctions/commandes.
Cas d'utilisation - Un pipeline ETL
Examinons maintenant un exemple réel de nettoyage de données - Un pipeline de données ETL.
Qu'est-ce qu'ETL ?
ETL signifie Extraire, Transformer et Charger. Il s'agit d'un processus de transfert de données d'un système à un autre à des fins de stockage et de traitement ultérieur.
Description du projet
Il existe un fabricant de téléphones intelligents avec des centaines de machines différentes.
Pour avoir une idée de la productivité, nous voulons obtenir le statut de fabrication en temps réel en plus des informations concernant chaque ligne de production des différentes machines. De plus, nous souhaitons que ces informations soient affichées sur un tableau de bord, et ce en temps réel, avec des analyses, des statistiques et des graphiques.
Un flux de travail simple pour ce processus ressemblerait à : Machines ⮕ Données de journal ⮕ Stockage de données ⮕ Service API ⮕ Tableau de bord de l’interface utilisateur
Voici comment:
Ce que fera cet ETL c’est d'extraire les enregistrements de fabrication qui consistent en un tas d'observations provenant des données de chaque machine. En surveillant ces observations, nous pouvons immédiatement détecter les erreurs et les valeurs aberrantes et les envoyer à un système d'alarme. Cependant, les journaux de ces machines ne sont PAS propres. Nous allons maintenant effectuer un traitement sur les données en provenance des journaux pour nous assurer qu'à la fin, nous avons des données propres qui iront à un modèle de machine ou un stockage de données pour une analyse plus approfondie.
Notre tâche
Nous prendrons le fichier journal comme notre INPUT à traiter. Quant à la SORTIE, nous aurons les données propres exportées vers un CSV. (Un vrai processus ETL écrit les données propres dans un stockage de données à la fin, nous n'effectuerons pas cette partie, nous nous concentrerons uniquement sur la gestion des données brutes).
Entrées
L'ensemble de données que nous utiliserons est un journal extrait d'une véritable machine CNC.
Qu'y a-t-il dans ce fichier journal ?
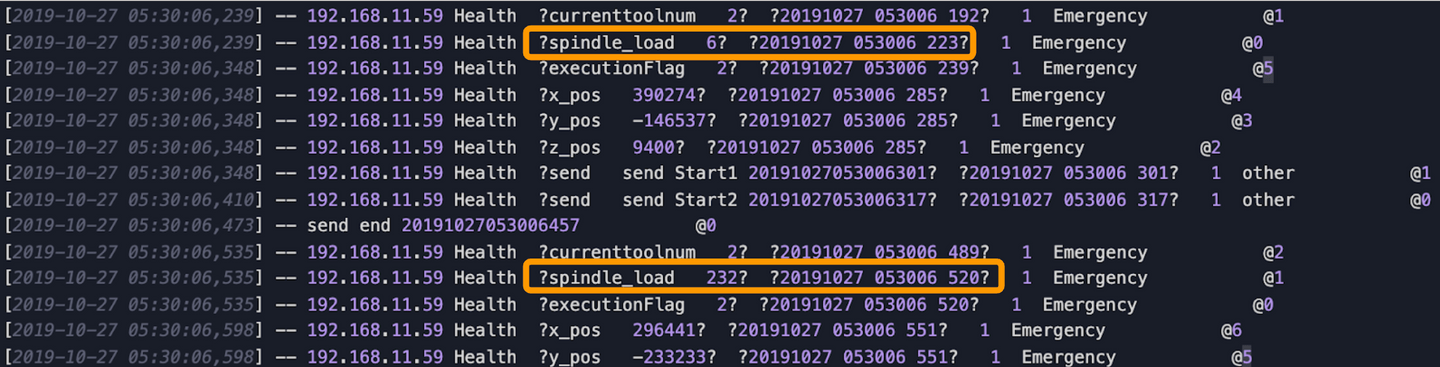
Jetons un coup d'œil à la première ligne, de gauche à droite, nous avons l' horodatage, l'adresse IP du serveur, quelques observations et ses valeurs et l'horodatage de la machine CNC.
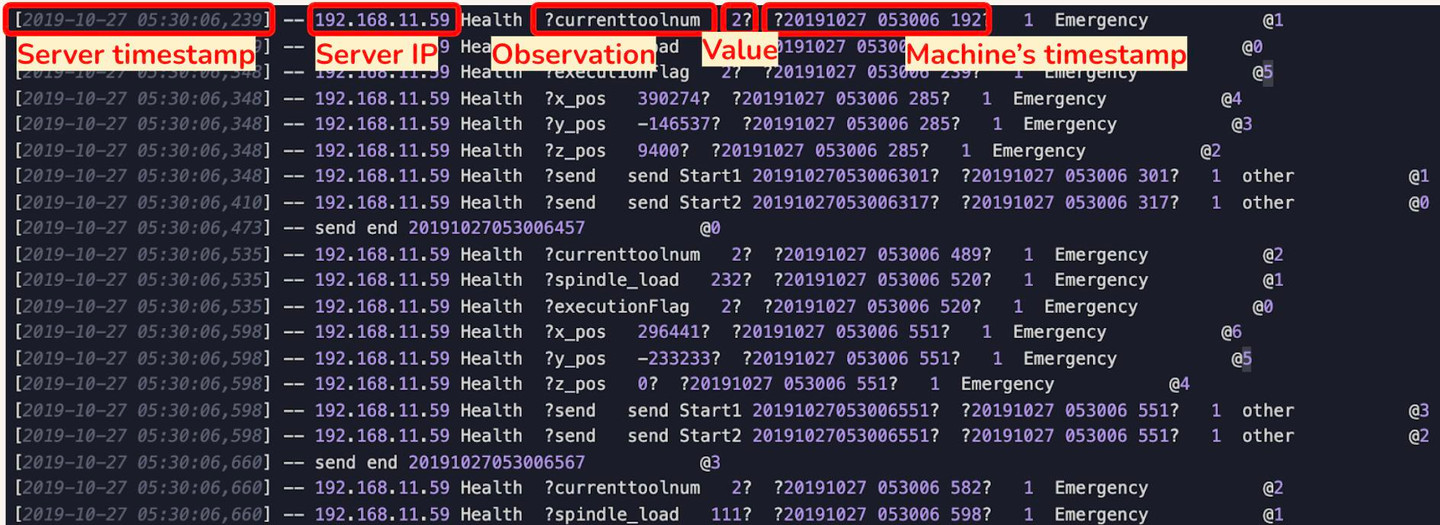
Notre objectif est « d'extraire les données dont nous avons besoin ». Dans ce cas nous ne prendrons que 3 choses (celles qui sont encerclées en jaune ci-dessous) :
- Toutes les observations
- Les valeurs des observations
- L’horodatage de la machine CNC
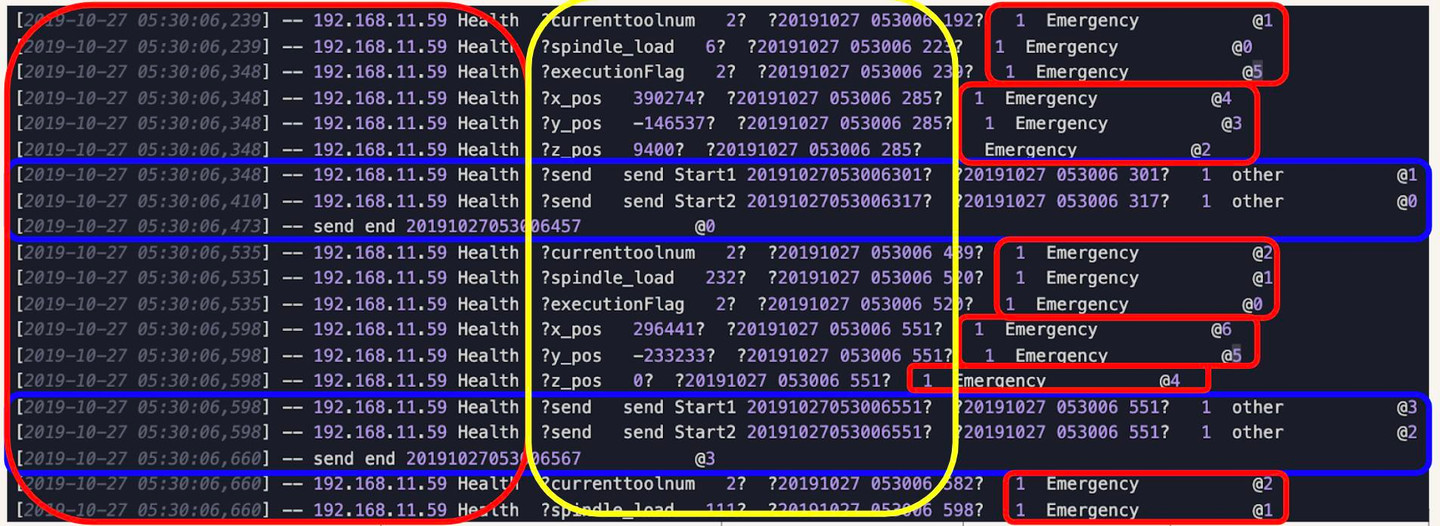
Le reste (cerclé en rouge et bleu) nous les laisserons tomber. (Nous supprimons les lignes qui n'ont pas d'observations, celles qui sont encerclées en bleu)
⮕ La suppression des données indésirables est l'une des tâches les plus courantes pour le nettoyage des données.
Sortie
Pour générer la sortie souhaitée, nous prendrons l' horodatage de la machinecomme index de ligne, les observations comme noms de colonne et les valeurs seront les données de ligne. Par exemple, la première observation que nous avons est currenttoolnum avec la valeur 2, l'horodatage généré est 20191027053006.192:
[2019-10-27 05:30:06,239] -- 192.168.11.59 Health ?currenttoolnum 2? ?20191027 053006 192? 1 Emergency @1
Par conséquent, notre sortie pour le premier enregistrement sera :
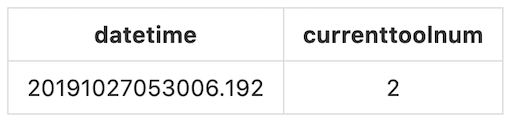
Si nous suivons cette convention pour le reste des enregistrements, à la fin, la sortie devrait ressembler à :
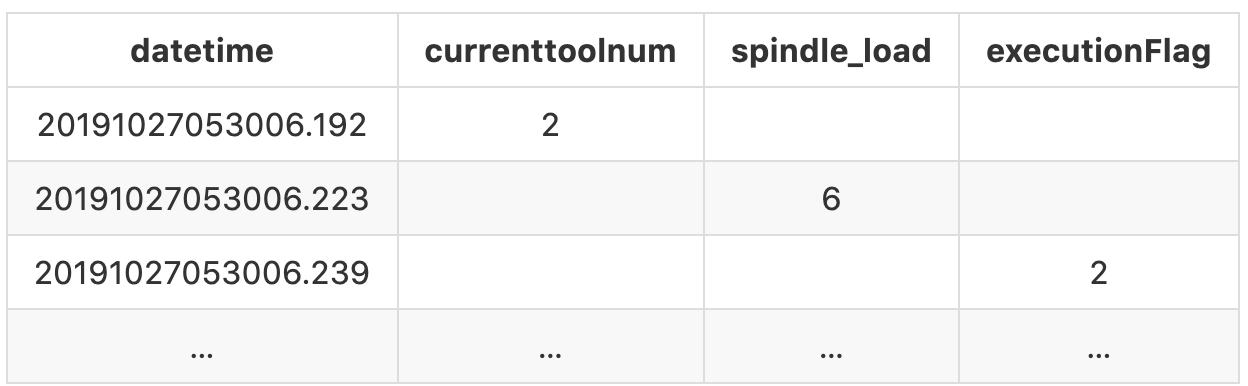
Il y a encore une chose que nous devons faire. Dans ce fichier journal, certaines observations peuvent apparaître plus d’une fois et parfois la valeur varie.
Par exemple, le premier spindle_load (le deuxième enregistrement dans le fichier journal) que nous obtenons est à20191027053006.223avec la valeur 6, la prochaine fois que nous obtenons est à 20191027053006.520 c’est avec la valeur 232. Cela signifie que pendant cette période de temps, la valeur de spindle_load est 6 et elle restera 6 jusqu'à la prochaine valeur valide que nous obtenons. Dans ce cas, spindle_load vaut 6 entre 20191027053006.223et 20191027053006.520, et il passe à 232à partir de 20191027053006.520.
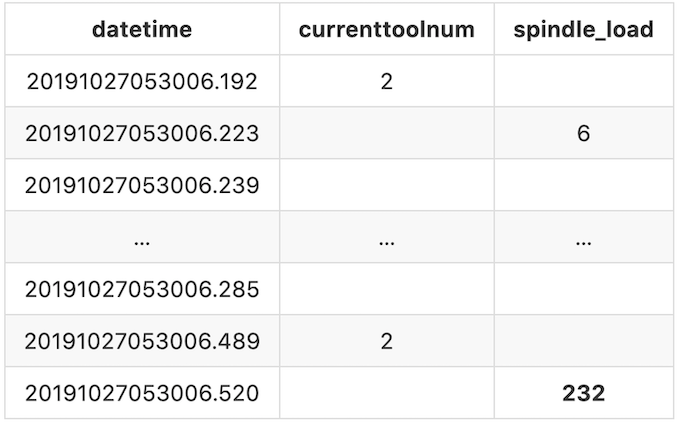
Pour pouvoir représenter cela clairement, nous remplirons les valeurs manquantes avec la valeur valide précédente jusqu'à ce qu’une valeur différente apparaisse. Après avoir rempli les valeurs manquantes, notre sortie finale ressemblerait à :
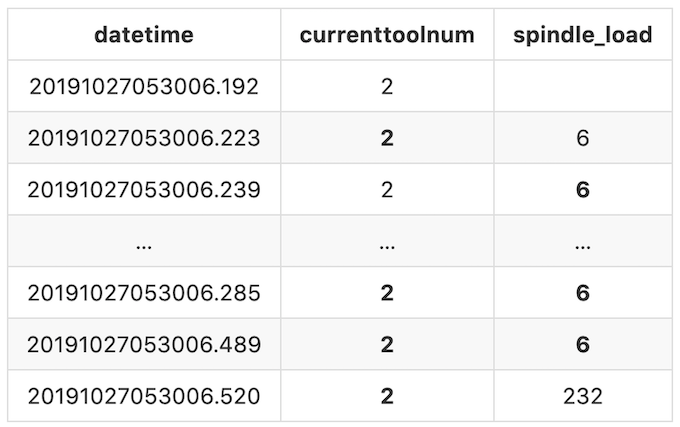
Maintenant avons clarifier l’ensemble des données et nos objectifs, commençons à nettoyer les données !
1. Importez le jeu de données
import pandas as pd
# Import the dataset into Pandas dataframe
raw_dataset = pd.read_table("test_data.log", header = None)
print(raw_dataset)
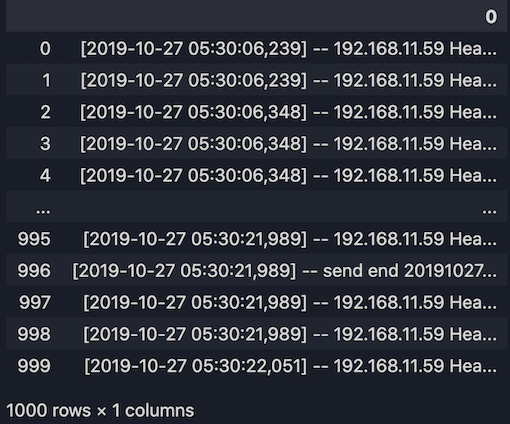
2. Convertissez le jeu de données en une liste
dataset_list = list(raw_dataset[0])
print(dataset_list)
Sortie:
['[2019-10-27 05:30:06,239] -- 192.168.11.59 Health ?currenttoolnum 2? ?20191027 053006 192? 1 Emergency @1',
'[2019-10-27 05:30:06,239] -- 192.168.11.59 Health ?spindle_load 6? ?20191027 053006 223? 1 Emergency @0',
'[2019-10-27 05:30:06,348] -- 192.168.11.59 Health ?executionFlag 2? ?20191027 053006 239? 1 Emergency @5',
...]
3. Divisez la ligne par un espace
# [:14]--> We only need the first 14 columns of the dataset.
line_split = [line.split(' ')[:14] for line in dataset_list]
long_df = pd.DataFrame(line_split)
print(long_df)
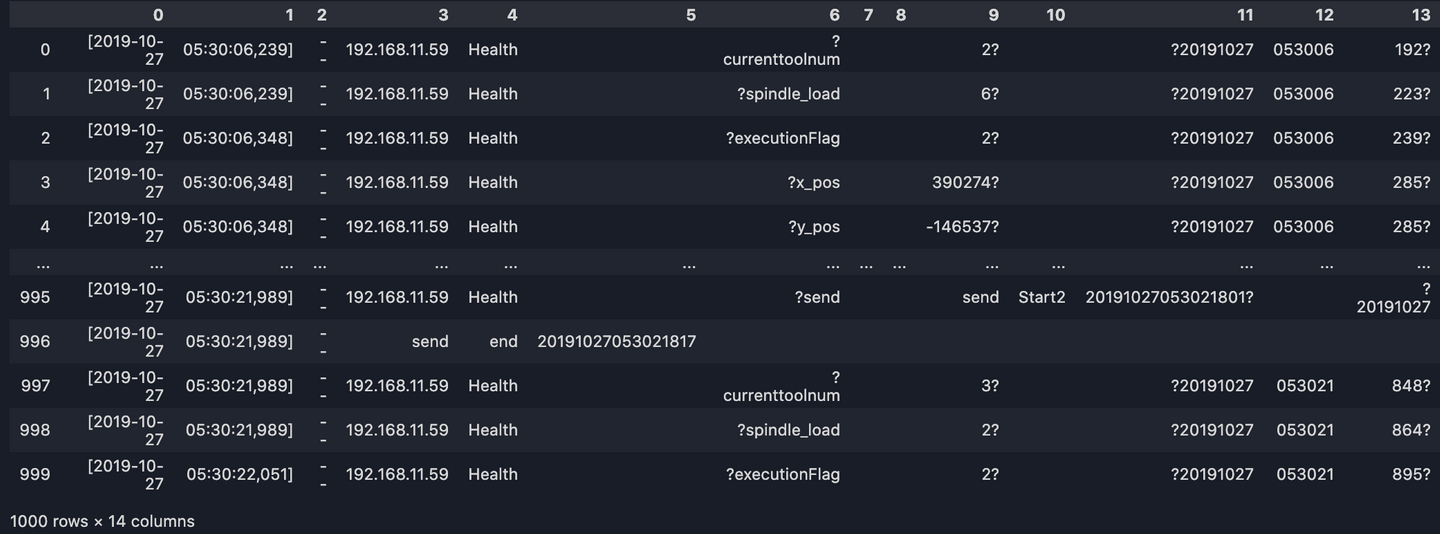
4. Supprimez les points d'interrogation
Des points d'interrogation gênants apparaissent dans les colonnes 6, 9, 11 et 13. Pour les supprimer :
long_df[6] = list(map(lambda s: s.replace('?', ''), long_df[6]))
long_df[9] = list(map(lambda s: s.replace('?', ''), long_df[9]))
long_df[11] = list(map(lambda s: s.replace('?', ''), long_df[11]))
long_df[13] = list(map(lambda s: s.replace('?', ''), long_df[13]))
print(long_df)
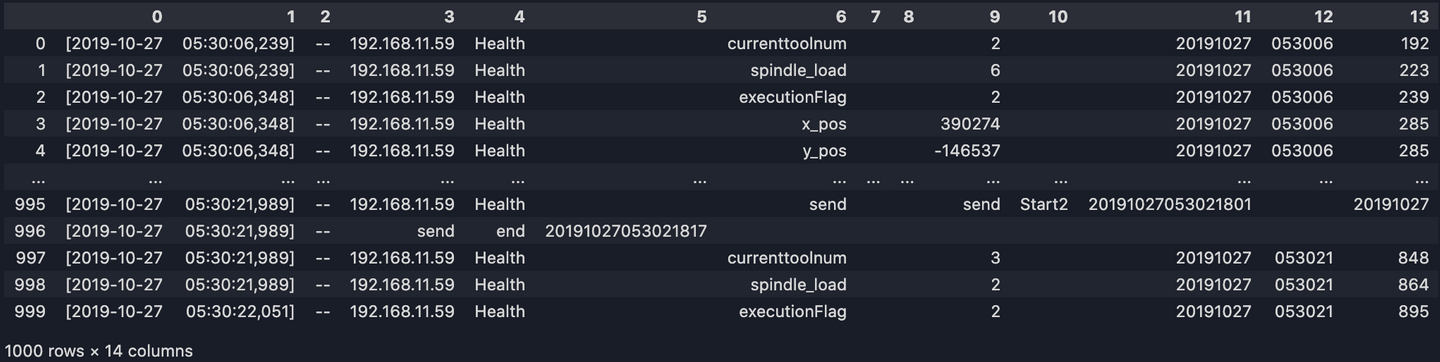
5. Obtenir les colonnes dont nous avons besoin
Ici, nous ne prenons que les observations, valeurs et l'horodatage de la machine:
long_df = long_df.loc[:, [6, 9, 11, 12, 13]]
print(long_df)
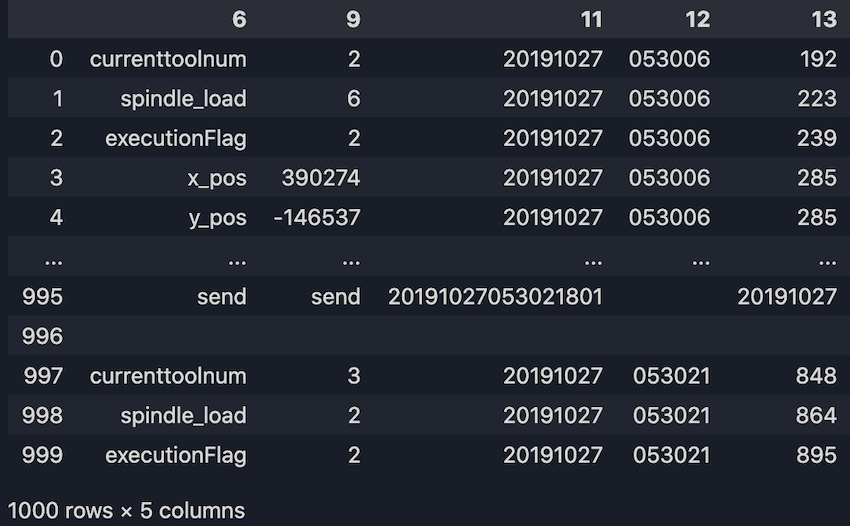
6. Prenez tous les arguments de la colonne 6 comme colonnes de notre dataframe
Nous transformerons toutes les observations en noms de colonnes :
all_columns = list(set(long_df[6].tolist()))
# Remove the data we don't need
all_columns.remove('')
all_columns.remove('send')
# Sorting the list
all_columns.sort()
print(all_columns)
Sortie:
['F_actual', 'OPmode', 'OPstate', 'RPM_actual', 'currenttoolnum', 'cuttingTime', 'cycletime', 'executionFlag', 'feedF', 'feedratio', 'inspectionData', 'line_name', 'machine_num', 'operatingTime', 'poweronTime', 'shop_name', 'spindle_load', 'spindle_temp', 'spindleratio', 'tool_current_life_01', 'tool_current_life_02', 'tool_current_life_03', 'tool_current_life_04', 'tool_current_life_05', 'tool_current_life_11', 'tool_current_life_12', 'tool_current_life_13', 'tool_current_life_14', 'tool_current_life_15', 'tool_preset_life_01', 'tool_preset_life_02', 'tool_preset_life_03', 'tool_preset_life_04', 'tool_preset_life_05', 'tool_preset_life_11', 'tool_preset_life_12', 'tool_preset_life_13', 'tool_preset_life_14', 'tool_preset_life_15', 'workcount', 'x_pos', 'y_pos', 'z_pos']
- Remodelez le
- long_df
- du format long au format large et prenez l'horodatage comme index de ligne
column_count = len(all_columns)
pre_time = ''
record = []
records_list = []
for line in dataset_list:
str_list = line.split(' ')
if str_list[6] != '' and str_list[6][0] == '?' and str_list[11][0] == '?':
request = str_list[6][1:]
if request in all_columns:
date = str_list[11][1:5] + str_list[11][5:7] + str_list[11][7:]
time = str_list[12][0:2] + str_list[12][2:4] + str_list[12][4:]
millisec = str_list[13][:-1]
cur_time = date + time + '.' + millisec
response = str_list[9].replace('?', '')
if cur_time != pre_time:
if record != []:
records_list.append(record)
record = [cur_time] + ['' for i in range(column_count)]
pre_time = cur_time
record[all_columns.index(request) + 1] = response
records_list.append(record)
df = pd.DataFrame(records_list, columns=['date_time'] + all_columns)
print(df)
Maintenant, notre jeu de données devrait ressembler à :
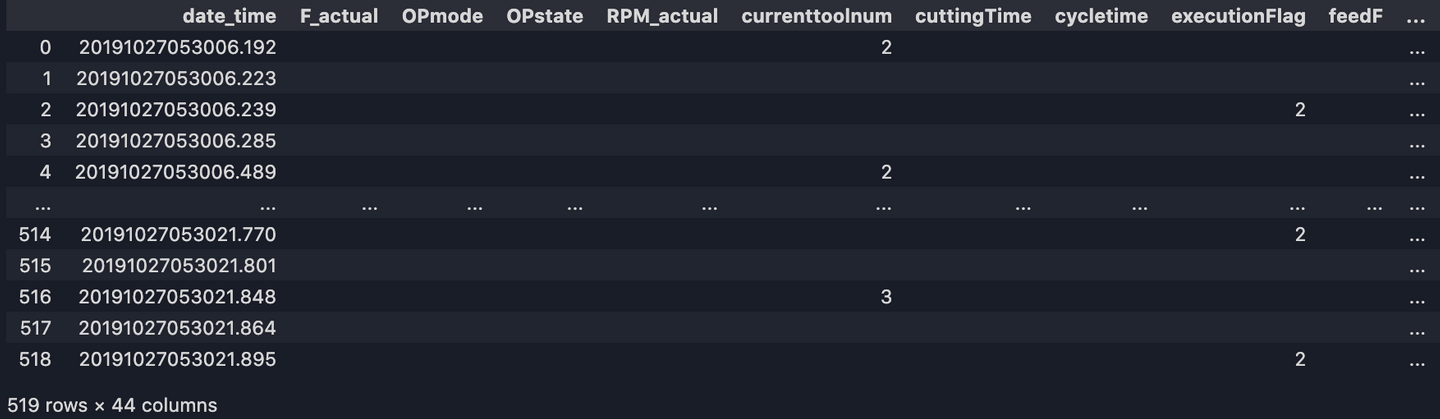
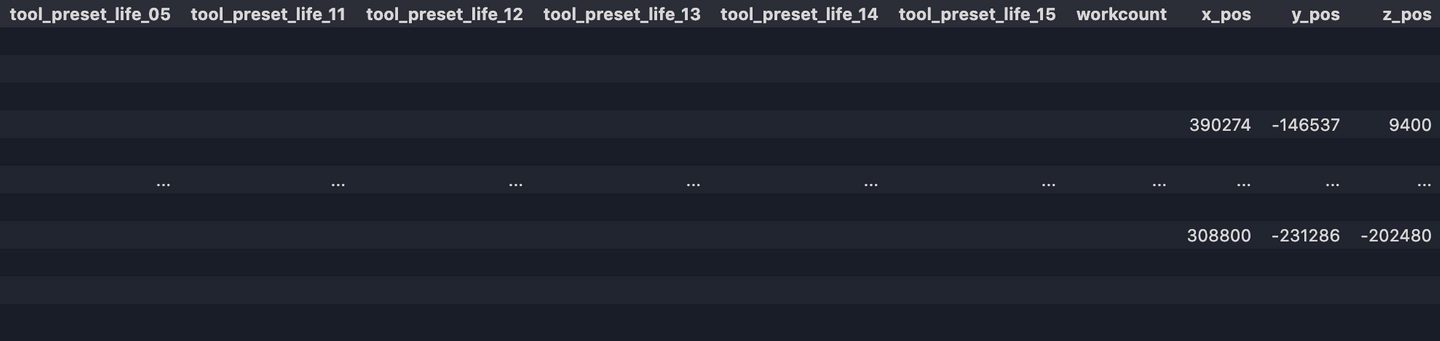
8. Convertir les types de données, réinitialiser l'index, remplacer les valeurs vides NAN
# Convert argument to a numeric type. (The default return dtype is float64 or int64 depending on the data supplied)
df[all_columns] = df[all_columns].apply(pd.to_numeric, errors='ignore')
# Reset index (optional)
df = df.reset_index(drop=True)
# Replace empty values with Pandas NAN
df = df.replace('', np.nan)
# Export to CSV
df.to_csv('output/df.csv')
Maintenant notre sortie df.csv ressemble à:
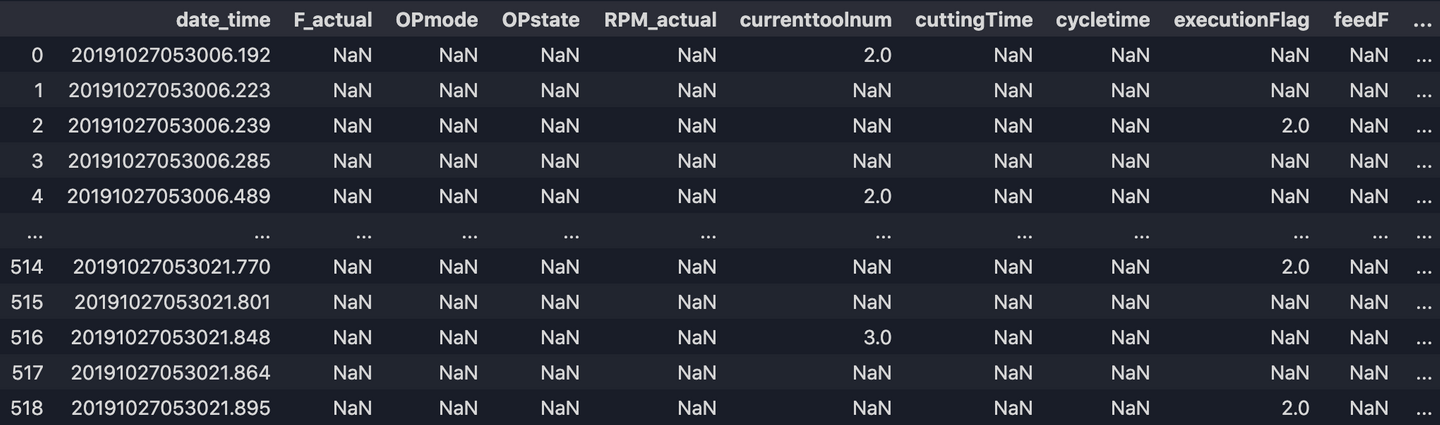
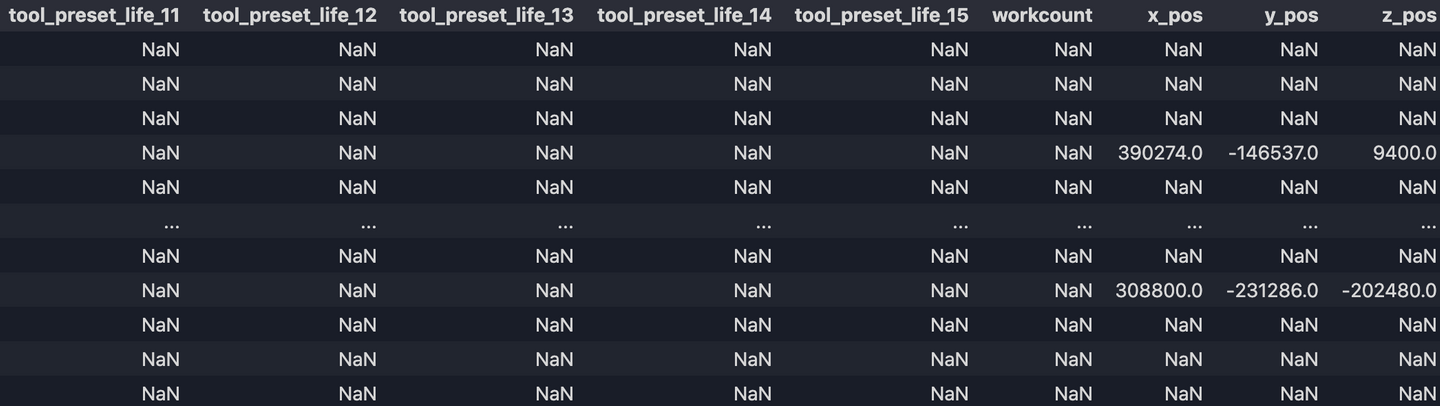
9. Remplir les valeurs manquantes
Dernière étape ! Remplissons les valeurs manquantes avec ffill(), qui signifie 'forward fill' et cela propagera la dernière observation valide.
df = df.ffill()
df.to_csv('output/df_new.csv')
Enfin nous avons notre sortie finale.
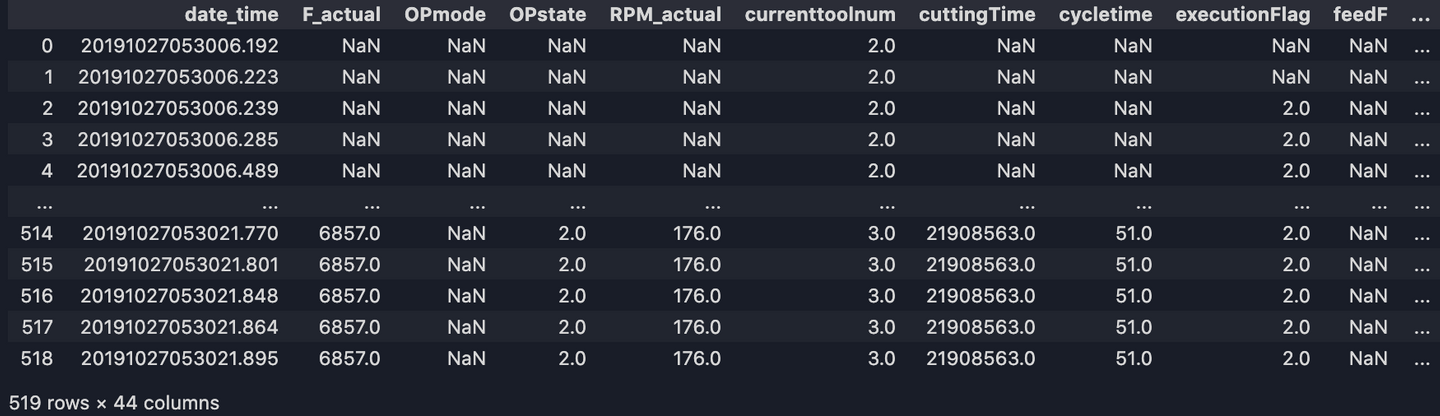
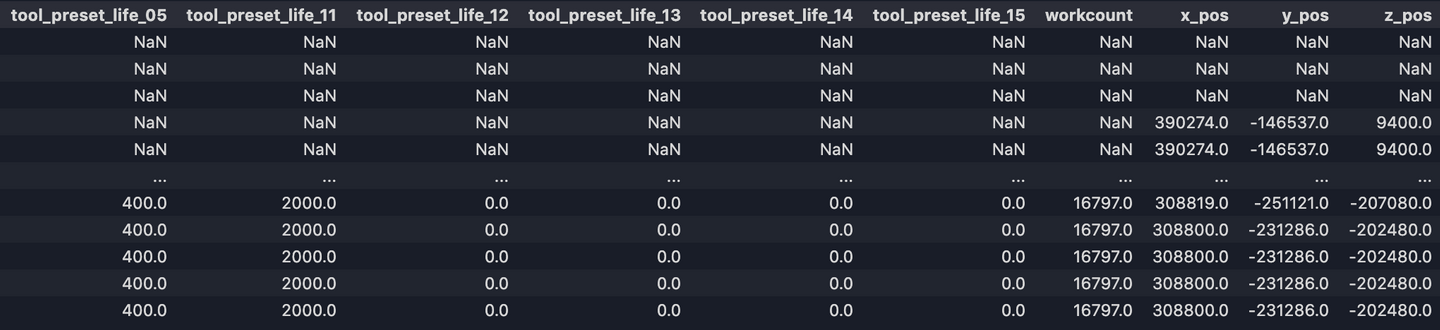
Avec cet ensemble de données propres nous sommes maintenant prêts à effectuer une analyse plus approfondie, à traiter ou à écrire dans un stockage de données pour les requêtes API! Si vous souhaitez en savoir plus et si vous cherchez à avoir une meilleure compréhension du traitement des données avec Python, jetez un œil à mon deuxième blogue sur le sujet.


Cet article vous a donné des idées ? Nous serions ravis de travailler avec vous ! Contactez-nous et découvrons ce que nous pouvons faire ensemble.


-min.jpg)



