TVA Sports

Le contexte
Plus important diffuseur sportif francophone en Amérique du Nord et première source d’information sur la LNH, la MLB et la MLS, TVA Sports a de nombreux téléspectateurs fidèles à qui il propose des tonnes de contenu pertinent chaque jour, chaque heure et même chaque minute.
Détails du projet
Le défi
On a dû trouver une façon d’accéder au flux de télévision en direct à partir de différents diffuseurs en ligne. Côté conception, l’un des aspects les plus importants de notre travail était de faire en sorte que les tableaux de statistiques soient faciles à lire, peu importe le sport ou la taille de l’écran. Restait ensuite les détails : sélection des statistiques pertinentes, ordre de présentation, sélection de la meilleure famille de polices ainsi que de la taille et du poids des caractères (à la lumière de beaucoup de recherches, de discussions et d’essais) et choix de l’abréviation ou du sigle approprié pour chaque colonne. Après avoir fait quelques tests et pris nos décisions, on savait que l’application allait connaître un franc succès.


La mission
Ce diffuseur a fait appel à nous parce qu’il cherchait un moyen rapide et efficace de transmettre des statistiques et des nouvelles plus pertinentes et plus souvent mises à jour que l’application originale. Mais notre client souhaitait surtout réduire au minimum le délai de transmission des notifications lorsqu’une action se déroulait en direct (un but ou une pénalité). Notre équipe a donc collaboré avec le client pour mettre au point un moyen novateur et fiable de recueillir et de diffuser les statistiques.




Le résultat
Notre client avait une vision assez claire de ce qu’elle voulait pour la nouvelle application. Comme on le fait pour tous nos clients, on a aussi proposé d’autres caractéristiques qui, selon nous, amélioreraient l’expérience de l’utilisateur, par exemple une présentation plus claire visuellement des statistiques générales d’une équipe, ou l’ajout de liens renvoyant à du contenu connexe au bas des articles pour inciter l’utilisateur à explorer d’autres sujets, et donc à passer plus de temps dans l’appli.
La suite...



Perspectives
Portraits Osedea : IA, aventures et culture avec Isabelle Bouchard

Dans le cadre de notre série Portraits d'Osedea, rencontrez aujourd'hui Isabelle Bouchard, développeuse senior et spécialiste en machine learning. Animée par une insatiable curiosité, Isabelle explore avec passion le monde de l'IA et ses applications pour le bien-être de tous. Au-delà de son expertise aiguisée, découvrez une femme pétillante et inspirante qui nous fera partager ses passions et les multiples facettes de sa personnalité.
D'où vient ton intérêt pour la science et l’intelligence artificielle ?
C’est un peu par hasard (ou par chance !) que je me suis orientée vers une carrière en intelligence artificielle. Au départ, j’ai étudié en génie biomédical. À la fin de mes études, bien que j'aie eu un intérêt, j'avais très peu d’expérience en développement logiciel et encore moins en intelligence artificielle. En fait, je n'avais jamais entendu parler du concept de machine learning (ML) avant d'en explorer les techniques dans mon premier emploi.
J’ai tout de suite aimé le fait que cela demande à la fois des compétences en mathématiques et en développement logiciel, ainsi qu'une bonne capacité à décomposer un problème. J'ai parcouru un petit bout de chemin en autodidacte, soutenue par des collègues qui m'ont beaucoup aidée à progresser. J'ai ensuite décidé de faire une maîtrise pour formaliser mes apprentissages et développer une expérience de recherche.

Qu’est-ce qui te passionne le plus en IA ?
J’apprécie particulièrement le dynamisme de ce domaine, qui évolue très rapidement. Je suis constamment mise au défi et je dois apprendre de manière continue pour pouvoir rester à jour avec les technologies.
De plus, les applications de l’IA sont infinies, ce qui me permet d’explorer de nouveaux domaines d'application. Ces dernières années, j'ai travaillé sur des projets en santé, en agriculture, en urbanisme, et bien d’autres domaines. C’est extrêmement stimulant.
Dans des secteurs de pointe comme l’intelligence artificielle, les femmes ne représentent que 22 % des professionnels. De plus, les femmes ne représentent que 28 % des diplômés en ingénierie et 40 % des diplômés en informatique. Selon toi, qu’est-ce qui explique le faible nombre de femmes en technologie, en ingénierie et en intelligence artificielle ?
Il y a plusieurs raisons pour lesquelles les femmes choisissent des domaines autres que ceux des technologies, mais il est clair pour moi que l’absence de modèles féminins en est une qui pèse lourd dans la balance. Cela explique également pourquoi plusieurs femmes choisissent de quitter le domaine, où elles ne se sentent pas toujours à leur place. On développe naturellement des affinités avec les personnes qui nous ressemblent, donc il est parfois plus difficile de trouver des alliés ou des mentors lorsqu’on est une femme dans un milieu occupé en majorité par des hommes. On a aussi une idée préconçue assez bien définie du développeur type, et cela peut faire peur quand on ne s’y identifie pas. Personnellement, cela m’a longtemps affectée, mais j’ai appris avec le temps à reconnaître que, clairement, je ne correspondrai jamais à ce profil, mais que c’est plus souvent vu comme une force qu’une faiblesse.
Comment envisages-tu l'impact de l'IA et de l'apprentissage automatique sur les industries dans les années à venir, en particulier dans des domaines tels que la santé, la finance et la technologie ?
J’espère voir l’IA assister les humains, plutôt que les remplacer, surtout en santé. Nos systèmes manquent de plus en plus d’humanité, et j’espère que nos dirigeants seront en mesure de comprendre comment utiliser les technologies pour nous rendre plus efficaces, mais sans perdre de vue l’importance des rapports humains. On comprendra que je ne suis pas nécessairement du genre optimiste ! L’IA et les technologies en général offrent des possibilités infinies, encore faut-il savoir les utiliser à bon escient.
Comment l’équipe IA chez Osedea intègre-t-elle les principes éthiques dans la conception et le déploiement de solutions basées sur l'IA ?
L’éthique des projets d’IA repose encore en grande partie sur les personnes qui les développent. Je répondrais donc spontanément que tout commence par l’embauche de personnes qui ont ces enjeux à cœur. Ensuite, dans notre processus d’analyse des besoins d’un projet, nous avons plusieurs points de contrôle pour nous assurer de soulever et de mitiger les principaux risques éthiques. Par exemple, nous analysons les jeux de données utilisés pour l'entraînement de nos modèles d’IA pour nous assurer de ne pas favoriser un segment d’utilisateurs au détriment d’un groupe sous-représenté dans les données.
Quelle serait ta retraite idéale ?
En santé ! J’adore le plein air. J’aimerais avoir une retraite remplie d’aventures qui me permettraient de continuer à me dépasser physiquement et mentalement, et à m'émerveiller devant la nature. Le tout accompagné de mon partenaire d’aventure préféré, de notre famille et de nos amis… et, bien sûr, entrecoupé de bons moments de détente !

As-tu un film ou un livre coup de cœur à recommander, et pourquoi ?
Puisqu’on vient de terminer la saison des Oscars, je ne peux pas passer à côté du merveilleux film "Poor Things", avec l’incroyable performance de l’actrice Emma Stone. Je le recommande fortement, comme tous les films de Yorgos Lanthimos, pour le scénario recherché et les personnages complètement déstabilisants.
Je recommande également la lecture du classique de la littérature américaine "Les Raisins de la Colère", de John Steinbeck. C'est un roman qui a été publié en 1939, mais qui raconte de manière très juste et toujours actuelle l’expérience humaine de ceux qui perdent à la loterie de la vie et qui se retrouvent du côté de la misère. Ce roman m’a profondément marquée.
Quelle est ta meilleure et ta pire habitude ?
Ma meilleure habitude, c’est d’être active. C’est un effort constant, mais ça m’est tellement bénéfique que j'en fais une priorité au quotidien. Ma pire habitude...procrastiner, clairement !

Quel est ton plus beau voyage et pourquoi ?
Un voyage en Turquie, en 2015, alors que je venais de terminer mon baccalauréat. Pour la richesse de la culture, les paysages grandioses et les villes absolument vibrantes, mais surtout pour l’incroyable sentiment de liberté que j’ai eu la chance de vivre en voyageant au début de la vingtaine. Sans un sou ni contrainte de temps, on se laissait réellement porter par les rencontres et les opportunités qui s’offraient à nous. Je sais que jamais je ne pourrai reproduire de pareilles circonstances, c’était magique !

Si tu pouvais posséder une compétence instantanément, laquelle choisirais-tu et comment l'utiliserais-tu dans ta vie quotidienne ?
J'aimerais posséder une aisance à m’exprimer à l’oral, sur le vif, de façon claire et concise. J’admire vraiment les gens qui le font naturellement ! Et c’est simple, j’appliquerais cette compétence dans toutes les sphères de ma vie, tant au niveau personnel que professionnel. La communication est tellement importante dans toutes les relations qu’on entretient. Ce qui serait magique, ce serait d'être capable de le faire en plusieurs langues !
Approche minimaliste de DataOps et MLOps avec DVC et CML

Dans cet article, nous examinerons l'importance cruciale de DataOps et MLOps dans le développement logiciel et en IA. Nous présenterons une approche MVP pratique, mettant l'accent sur l'utilisation de DVC (Contrôle de Version de Données) et CML (Apprentissage Automatique Continu), intégrés à Git, pour illustrer efficacement ces concepts.
- Approche Pratique : En utilisant DVC et CML, nous démontrerons une approche pratique de produit minimal viable (MVP) pour DataOps et MLOps.
- Intégration avec Git : En mettant en évidence l'intégration fluide de ces outils avec Git, nous montrerons comment les flux de travail familiers peuvent être améliorés pour la gestion des données et des modèles.
- Implémentation Efficace : Notre objectif est de fournir des directives claires pour implémenter efficacement les pratiques DataOps et MLOps.
Problèmes Courants dans les Projets AI & Data
- "Quelle Version de Données ?" Perdez-vous constamment la trace de la version de données utilisée pour l'entraînement du modèle ?
- "Le Nouveau Modèle Est-il Bon ?" Arrêtez de vous demander si votre dernier modèle bat l'ancien ou ce qui a changé entre eux.
- "Pourquoi Notre Dépôt Est-il Si Lourd ?" Dépôt GitHub surchargé avec des données ?
Compréhension de DataOps et MLOps
DataOps et MLOps sont des pratiques fondamentales pour le développement logiciel moderne, en particulier en IA. Ces approches sont essentielles pour gérer efficacement les cycles de vie des données et des modèles d'apprentissage automatique.
- Scalabilité : Gérer efficacement les données (DataOps) et les modèles d'apprentissage automatique (MLOps) est essentiel pour construire des systèmes d'IA évolutifs et robustes, cruciaux pour les projets de développement logiciel.
- Performance et Fiabilité : La mise en œuvre de ces pratiques garantit des performances système constantes et une fiabilité, ce qui est particulièrement vital pour les start-ups opérant dans des environnements dynamiques et contraints en ressources.
- Éviter les Pièges : De nombreuses équipes de développement ont besoin de versionner correctement les données et les modèles ou adoptent une approche réactive de la gestion système, ce qui entraîne des défis significatifs en matière de reproductibilité et d'augmentation des taux d'erreur, entravant la croissance et l'innovation.
Comprendre et intégrer DataOps et MLOps dans les flux de travail n'est pas seulement bénéfique ; c'est une nécessité stratégique.
L'Approche MVP
L'approche MVP (Produit Minimal Viable) en DataOps et MLOps consiste à s'aligner sur les principes fondamentaux du Manifeste Agile, en mettant l'accent sur la simplicité, l'efficacité et le déploiement.
- Principes Agiles : Mettez l'accent sur la simplicité, l'efficacité et les processus axés sur les personnes, favorisant la flexibilité et la réactivité dans la gestion de projet.
- Réduire la Dépendance aux Systèmes Complexes : Plaidez pour une minimisation de la dépendance aux systèmes SaaS complexes et propriétaires, maintenant ainsi le contrôle et la flexibilité dans votre développement.
- Outils Efficaces : Exploitez des outils comme DVC et CML qui s'intègrent avec les flux de travail Git familiers ; cette approche garantit une adoption fluide et améliore la collaboration et l'efficacité de l'équipe.
Adopter une approche MVP signifie créer des flux de travail en DataOps et MLOps plus agiles, adaptables et efficaces, permettant le développement de solutions robustes et évolutives sans être encombré par des complexités inutiles.
Pratique
Maintenant, nous plongeons dans les aspects pratiques de la mise en place d'un environnement Python et de l'utilisation d'outils essentiels comme DVC, CML et SciKit-Learn. Nous passerons par la configuration d'un dépôt GitHub pour un contrôle de version efficace et démontrerons la construction et l'évaluation d'un modèle en utilisant SciKit-Learn dans un calepin Jupyter.
- Configuration : Configurez un environnement Python et installez DVC, CML et SciKit-Learn.
- Construction de Modèle : Utilisez SciKit-Learn avec un ensemble de données intégré dans un calepin Jupyter pour une démonstration simple d'entraînement et d'évaluation de modèle.
- Processus Simplifié : Configurez GitHub et Git pour exécuter et évaluer votre modèle.
Installez l'Environnement Python
Nous utiliserons Poetry pour gérer notre environnement Python. Poetry est un outil de gestion de dépendances Python qui vous permet de créer des environnements reproductibles et d'installer facilement des packages.
# Install Poetry
pipx install poetry
# Init Poetry project
poetry init
# Add dependencies
poetry add dvc cml scikit-learn
Chargement des données
Nous utiliserons l'ensemble de données sur leBreast Cancer Data Set de UCI Machine Learning Repository.
Caractéristiques clés :
- Nombre d'Instances : 569
- Nombre d'Attributs : 30 attributs numériques prédictifs, plus la classe.
- Attributs : Mesures telles que le rayon, la texture, le périmètre, la zone, la régularité, la compacité, la concavité, les points concaves, la symétrie et la dimension fractale.
- Distribution des Classes : 212 Malignes, 357 Bénignes.
import sklearn.datasets
# Load dataset
data = sklearn.datasets.load_breast_cancer(as_frame=True)
print(data.data.info())
Mise en Œuvre de Paramètres Externes pour les Ajustements de Données et de ModèlesNous utiliserons des fichiers de configuration externes, comme settings.toml, pour ajuster dynamiquement les paramètres des données et du modèle. Cette approche ajoute de la flexibilité à notre projet et souligne l'importance de la versionnage et du suivi des changements, surtout lors de l'introduction de modifications intentionnelles ou de "bugs" à des fins de démonstration.
Dégradation des Données avec des Paramètres Externes
Parce que l'ensemble de données de démonstration fonctionne bien avec un modèle simple, nous allons dégrader artificiellement les données pour souligner l'importance du suivi des changements et de la versionnage.
- Configuration Externe : Utilisez settings.toml pour définir des paramètres comme num_features=1, qui dicte le nombre de fonctionnalités à utiliser à partir de l'ensemble de données.
- Manipulation des Données : Nous modifions dynamiquement nos données en lisant le paramètre num_features depuis settings.toml. Par exemple, en réduisant l'ensemble de données à une seule fonctionnalité :
python
import toml
settings = toml.load("settings.toml")
data.data = data.data.iloc[:, : settings["num_features"]]
print(data.data.info())
Entraînement du Modèle
We'll use SciKit-Learn to split the data and train a simple model.
python
import sklearn.model_selection
# Split into train and test
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
data.data, data.target, test_size=0.3, random_state=42
)
python
import sklearn.linear_model
# Train a simple logistic regression model
model = sklearn.linear_model.LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
python
# Evaluate the model
predictions = model.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(y_test, predictions)
print(f"Model Accuracy: {accuracy:.2f}")
Model Accuracy: 0.91
python
# View the classification report
report = sklearn.metrics.classification_report(y_test, predictions)
print(report)
# Export the report to a file
with open("report.txt", "w") as f:
f.write(report)
precision recall f1-score support
0 0.93 0.83 0.87 63
1 0.90 0.96 0.93 108
accuracy 0.91 171
macro avg 0.92 0.89 0.90 171
weighted avg 0.91 0.91 0.91 171
python
import seaborn as sns
import matplotlib.pyplot as plt
# Create a confusion matrix
confusion_matrix = sklearn.metrics.confusion_matrix(y_test, predictions)
# Plot the confusion matrix
sns.heatmap(confusion_matrix, annot=True, fmt="d")
# Export the plot to a file
plt.savefig("confusion_matrix.png")
Saving the Model and Data
We'll save the model and data locally to demonstrate DVC's tracking capabilities.
python
from pathlib import Path
# Save data
Path("data").mkdir(exist_ok=True)
data.data.to_csv("data/data.csv", index=False)
data.target.to_csv("data/target.csv", index=False)
python
import joblib
# Save model
Path("model").mkdir(exist_ok=True)
joblib.dump(model, "model/model.joblib")
Implementing Data and Model Versioning with DVC
Until now, we have covered the standard aspects of AI and machine learning development. We're now entering the territory of data versioning and model tracking. This is where the real magic of efficient AI development comes into play, transforming how we manage and evolve our machine-learning projects.
- Better Operations: Data versioning and model tracking are crucial for AI project management.
- Data Versioning: Efficiently manage data changes and maintain historical accuracy for model consistency and reproducibility.
- Model Tracking: Start tracking model iterations, identify improvements, and ensure progressive development.
Streamlining Workflow with DVC Commands
To effectively integrate Data Version Control (DVC) into your workflow, we break down the process into distinct steps, ensuring a smooth and understandable approach to data and model versioning.
Initializing DVC
Start by setting up DVC in your project directory. This initialization lays the groundwork for subsequent data versioning and tracking.
dvc init
Setting Up Remote Storage
Configure remote storage for DVC. This storage will host your versioned data and models, ensuring they are safely stored and accessible.
dvc remote add -d myremote /tmp/myremote
Versioning Data with DVC
Add your project data to DVC. This step versions your data, enabling you to track changes and revert if necessary.
dvc add data
Versioning Models with DVC
Similarly, add your ML models to DVC. This ensures your models are also versioned and changes are tracked.
dvc add model
Committing Changes to Git
After adding data and models to DVC, commit these changes to Git. This step links your DVC versioning with Git's version control system.
git add data.dvc model.dvc .gitignore
git commit -m "Add data and model"
Pushing to Remote Storage
Finally, push your versioned data and models to the configured remote storage. This secures your data and makes it accessible for collaboration or backup purposes.
dvc push
Tagging a Version
Create a tag in Git for the current version of your data:
git tag -a v1.0 -m "Version 1.0 of data"
Updating and Versioning Data
- Make Changes to Your Data:
-Modify your data.csv as needed. - Track Changes with DVC:
-Run dvc add again to track changes:
dvc add data
- Commit the New Version to Git:
- -Commit the updated DVC file to Git:
git add data.dvc
git commit -m "Update data to version 2.0"
- Tag the New Version:
- -Create a new tag for the updated version:
git tag -a v2.0 -m "Version 2.0 of data"
Switching Between Versions
- Checkout a Previous Version:
- -To revert to a previous version of your data, use Git to checkout the corresponding tag:
git checkout v1.0
- Revert Data with DVC:
- -After checking out the tag in Git, use DVC to revert the data:
dvc checkout
Understanding Data Tracking with DVC
DVC offers a sophisticated approach to data management by tracking pointers and hashes to data rather than the data itself. This methodology is particularly significant in the context of Git, a system not designed to efficiently handle large files or binary data.
How DVC Tracks Data
- Storing Pointers in Git:
-DVC stores small .dvc files in Git. These pointers reference the actual data files.
-Each pointer contains metadata about the data file, including a hash value uniquely identifying the data version.
- Hash Values for Data Integrity:
-DVC generates a unique hash for each data file version. This hash ensures the integrity and consistency of the data version being tracked.
-Any change in the data results in a new hash, making it easy to detect modifications.
- Separating Data from Code:
-Unlike Git, which tracks and stores every version of each file, DVC keeps the actual data separately in remote storage (like S3, GCS, or a local file system).
-This separation of data and code prevents bloating the Git repository with large data files.
Importance in the Context of Git
- Efficiency with Large Data:
-Git struggles with large files, leading to slow performance and repository bloat. DVC circumvents this by offloading data storage.
-Developers can use Git as intended – for source code – while DVC manages the data.
- Enhanced Version Control:
-DVC extends Git's version control capabilities to large data files without taxing Git's infrastructure.
-Teams can track changes in data with the same granularity and simplicity as they track changes in source code.
- Collaboration and Reproducibility:
-DVC facilitates collaboration by allowing team members to share data easily and reliably through remote storage.
-Reproducibility is enhanced as DVC ensures the correct alignment of data and code versions, which is crucial in data science and machine learning projects.
Using DVC as a Feature Store
DVC can be a feature store in machine learning workflows. It offers advantages such as version control, reproducibility, and collaboration, streamlining the management of features across multiple projects.
What is a Feature Store?
A feature store is a centralized repository for storing and managing features - reusable pieces of logic that transform raw data into formats suitable for machine learning models. The core benefits of a feature store include:
- Consistency: Ensures uniform feature calculation across different models and projects.
- Efficiency: Reduces redundant computation by reusing features.
- Collaboration: Facilitates sharing and discovering features among data science teams.
- Quality and Compliance: Maintains a single source of truth for features, enhancing data quality and aiding in compliance with data regulations.
Benefits of DVC in Feature Management
- Version Control for Features: DVC enables version control for features, allowing tracking of feature evolution.
- Reproducibility: Ensures each model training is traceable to the exact feature set used.
- Collaboration: Facilitates feature-sharing across teams, ensuring consistency and reducing redundancy.
Setting Up DVC as a Feature Store
- Organizing Feature Data: Store feature data in structured directories within your project repository.
- Tracking Features with DVC: Use DVC to add and track feature files (e.g., dvc add data/features.csv).
- Committing Feature Changes: Commit changes to Git alongside .dvc files to maintain feature evolution history.
Using DVC for Feature Updates and Rollbacks
- Updating Features: Track changes by rerunning dvc add on updated features.
- Rollbacks: Use dvc checkout to revert to specific feature versions.
Best Practices for Using DVC as a Feature Store
- Regular Updates: Keep the feature store up-to-date with regular commits.
- Documentation: Document each feature set, detailing source, transformation, and usage.
- Integration with CI/CD Pipelines: Automate feature testing and model deployment using CI/CD pipelines integrated with DVC.
Implementing a DVC-Based Feature Store Across Multiple Projects
- Centralized Data Storage: Choose shared storage that is accessible by all projects and configure it as a DVC remote.
- Versioning and Sharing Features: Version control feature datasets in DVC and push them to centralized storage. Share .dvc files across projects.
- Pulling Features in Different Projects: Clone repositories and pull specific feature files using DVC, enabling their integration into various workflows.
Best Practices for Managing a DVC-Based Feature Store Across Projects
- Documentation: Maintain comprehensive documentation for each feature.
- Access Control: Implement mechanisms to regulate access to sensitive features.
- Versioning Strategy: Develop a clear strategy for feature versioning.
- Automate Updates: Utilize CI/CD pipelines for updating and validating features.
Streamlining ML Workflows with CML IntegrationIntegrating Continuous Machine Learning (CML) is a game-changer for CI/CD in machine learning. It automates critical processes and ensures a more streamlined and efficient workflow.Setting Up CML WorkflowsCreate a GH Actions workflow within your GitHub repository, ensuring it is configured to run on every push or PR.name: model-training
on: [push]
jobs:
run:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install Poetry
run: pipx install poetry
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: "3.10"
cache: "poetry"
- name: Install dependencies
run: poetry install --no-root
- uses: iterative/setup-cml@v2
- name: Train model
run: |
make run
- name: Create CML report
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
echo "\`\`\`" > report.md
cat report.txt >> report.md
echo "\`\`\`" >> report.md
echo "" >> report.md
cml comment create report.md
Conclusion: Boosting Software and AI Ops
In wrapping up, we've delved into the core of DataOps and MLOps, demonstrating their vital role in modern software development, especially in AI. By mastering these practices and tools like DVC and CML, you're learning new techniques and boosting your skillset as a software developer.
- Stay Agile and Scalable: Adopting DataOps and MLOps is essential for developing in the fast-paced world of AI and keeping your projects agile and scalable.
- Leverage Powerful Tools: Mastery of DVC and CML enables you to manage data and models efficiently, making you a more competent and versatile developer.
- Continuous Learning and Application: The journey doesn’t end here. The true potential is realized in continuously applying and refining these practices in your projects.
This is more than just process improvement; it's about enhancing your development workflows to meet the evolving demands of AI and software engineering.
Comment on mène la barque chez Osedea (sans aucun patron)

Osedea a une structure organisationnelle tout à fait unique. Elle s’inspire de l’humanocratie, une approche inventée par Gary Hamel, chercheur à l’Université Harvard, dont l’argumentaire fondé sur les données incite à contourner la bureaucratie, à faire tomber les relations hiérarchiques et à changer l’ADN de l’entreprise pour que tous les membres de l’équipe aient des chances égales de réussir, de grandir et de contribuer.
Pour bien des travailleurs, c’est un concept tout nouveau, alors nous avons pensé vous faire part de nos réflexions et répondre à vos questions sur la réalité des entreprises qui, comme la nôtre, se sont dotées d’une telle structure.
Tout d’abord, qu’est-ce que la bureaucratie?
Nées au 18e siècle, les bureaucraties devaient servir à contrecarrer le népotisme (la pratique qui consiste à nommer des amis ou de la famille à des postes de pouvoir par voie de favoritisme). La bureaucratie devait également encadrer le travail au moyen de règles, de pratiques et de principes qui amèneraient un maximum de gens à se conformer. Plus tard au 20e siècle, le sociologue Max Weber a déclaré que plus la bureaucratie était déshumanisée, plus elle s’approchait de la perfection.
Vous avez probablement déjà travaillé dans une bureaucratie, puisque la vaste majorité des entreprises fonctionnent sur ce modèle :
- La hiérarchie est formelle (approche verticale à niveaux multiples).
- Le pouvoir est relié au poste (certains en ont plus que d’autres, selon leurs fonctions).
- Les supérieurs attribuent les tâches et évaluent le travail.
- Tout le monde compétitionne pour les promotions; la rémunération dépend de l’échelon.
Toutefois, les recherches de Gary Hamel ont révélé des faits troublants sur les bureaucraties :
- 79 % des personnes sondées estimaient que la bureaucratie ralentissait considérablement la prise de décision.
- 68 % disaient que, dans leur entreprise, les nouvelles idées suscitaient le scepticisme ou même l’opposition.
- 76 % trouvaient que les comportements politiques avaient une grosse influence sur l’avancement, au détriment de la compétence ou du potentiel.
Peut-être qu’un environnement hiérarchique traditionnel vous a déjà causé de la frustration? Voici pourquoi les entreprises s’y accrochent malgré tout :
- C’est un moyen bien connu d’inciter les humains à l’action.
- Il est difficile d’imaginer une autre façon de faire.
- C’est efficace jusqu’à un certain point : le travail se fait; il est facile de tout contrôler et coordonner; c’est cohérent.
- Puisque les bureaucraties existent depuis le 18e siècle, des millions de carrières se sont construites autour d’un désir de gravir les échelons et d’atteindre des postes de pouvoir. Or, les humains sont réfractaires au changement.
L’abandon de la bureaucratie habituelle demande du courage, de la créativité et une envie d’avoir une entreprise humaine. En tant que société, nous pouvons y travailler.
De la bureaucratie à l’humanocratie
Osedea est structurée autour des personnes, par opposition à la hiérarchie. Selon nous, les bureaucraties peuvent être déshumanisantes. Elles encouragent les mauvais comportements, les jeux de pouvoir et la politique. Les personnes qui y avancent ne sont pas nécessairement récompensées pour des comportements qui aident l’entreprise. La haute direction a plus tendance à avantager les personnes qui mettent leurs propres intérêts en priorité, qui excellent dans la « gestion ascendante » et qui savent lire les humeurs ou les besoins de leur gestionnaire (plutôt que ceux de l’entreprise) pour mieux y répondre.
Chez Osedea, nous avons opté pour « une structure sans gestionnaires ». C’est un peu différent d’une « structure horizontale », terme fort utilisé – souvent à tort – pour décrire une structure faite de seulement quelques échelons et d’une courte ligne d’autorité. Cette dernière survit difficilement à la croissance et se présente comme un rêve, mais se transforme en un cauchemar logistique et finit en chaos. Si vous voulez en apprendre plus sur les enjeux et avantages d'une structure horizontale, jetez un coup d'oeil à cet article de blogue.
Pourquoi une structure sans gestionnaires?
- Ce type de structure concorde avec notre vision de créer un monde de possibilités pour notre équipe tout en lui rendant la vie belle.
- Elle stimule énormément la créativité, l’apprentissage et l’autonomie.
- C’est une manière de cultiver l’ambition « horizontale » et non l’ambition « verticale », qui correspond au cheminement professionnel habituel, dans le cadre duquel une recrue gravirait les échelons au bout de plusieurs années de service : associé, gestionnaire, vice-président… L’ambition « horizontale » est une structure où les employés qui aiment leur travail sont encouragés à approfondir la chose, à étendre leurs connaissances et à s’améliorer. Cette horizontalité n’annule pas l’évolution. Toutefois, au lieu de récompenser les plus performants par des responsabilités de gestion, qui éloignent souvent les gens de ce qu’ils font réellement de mieux, nous leur offrons des responsabilités proches de leurs fonctions. Nous complétons le tout par des valeurs, des bénéfices et de l’autonomie.
- Tout le monde peut apporter sa pierre à l’édifice chez Osedea, peu importe l’expérience.
- Les résultats sont rapides.
- Les effets négatifs de la bureaucratie disparaissent.
Bien sûr, nous ne disons pas que tout est parfait dans notre structure. Il faut se rappeler que les entreprises évoluent constamment. Nous connaissons notre destination, mais nous rencontrerons des défis. Certains seront faciles à surmonter, d’autres nous suivront longtemps et d’autres encore apparaîtront en cours de route. Il est peut-être difficile d’imaginer comment une organisation peut fonctionner sans structure formelle, mais on se doit d’essayer.
Quelques idées reçues sur notre structure
Pas de gestionnaires, pas de leaders.
Il est important de comprendre que les gestionnaires ne sont pas toujours des leaders. Chez Osedea, nous ne croyons pas au leadership désigné. Le leadership se bâtit plutôt par un travail de qualité supérieure, par une curiosité à l’égard de ce que pourrait faire naître notre vision d’entreprise ainsi que par une influence naturelle sur les autres. Chaque projet a son « chef » ou son équipe initiatrice – qui s’occupe de rassembler les gens autour de la réalisation du projet et qui est la ressource par excellence. Mais nous ne croyons pas en une structure où une seule personne gère les développeurs, les concepteurs, les vendeurs… etc.
Sans gestionnaire, c’est le chaos : impossible de prendre des décisions.
Nous avons des processus efficaces pour tout, des attentes d’équipe et du leadership naturel. On pourrait penser que sans un chef pour statuer, il est impossible d’avancer ou de décider de quelque chose sans que tout le monde s’en mêle. En fait, les personnes qui sont responsables d’un projet, qui le comprennent dans son entièreté et qui connaissent bien le contexte doivent participer à la discussion. Mais au bout du compte, la décision repose sur les informations et les données en main et tient compte de notre vision, de nos valeurs, des parties concernées et des besoins d’entreprise.
Sans gestionnaire, je ne progresse pas dans ma carrière et je ne reçois ni retours, ni mentorat, ni accompagnement.
Nous croyons aux réussites professionnelles. Pour nous, au-delà des postes de direction, tous les chemins mènent au succès. Même si nous n’avons pas de gestionnaires, nous avons des processus et des indicateurs en place qui font en sorte que nos employés atteignent leur plein potentiel, reçoivent des commentaires et sont évalués et encadrés.
Puisqu'il n'y a pas de promotion, rien ne me motive à me dépasser ou à contribuer.
Chez Osedea, le bon travail est récompensé financièrement comme sur le plan des occasions professionnelles (ex. : nous envoyons nos développeurs donner des conférences à l’étranger, même s’ils n’ont pas d’ancienneté; notre développeur Full Stack Robin Kurtz a eu la chance de travailler en tête à tête avec Spot le robot). Nous sommes flexibles, nous pensons différemment, nous encourageons nos gens à s’éloigner des sentiers battus – et des parcours de carrière traditionnels –, et nous dirigeons les membres de l’équipe là où ils sont les plus efficaces et s’épanouissent le plus.
Votre structure est bonne tant que vous avez moins de 100 employés, mais vous n’arriverez pas à la maintenir si vous grossissez.
La croissance est la clé pour toute entreprise, mais si c’est au prix de notre approche d’humanocratie, non merci! Une structure comme la nôtre peut-elle survivre à long terme? OUI! Est-ce qu’il faudra faire des ajustements et des améliorations? OUI. C’est un travail constant. Nous nous accrochons à notre vision, ce qui ne veut pas dire que notre quotidien restera toujours le même.
Aujourd’hui, nous avons des bureaux à Montréal (au Canada) et à Nantes (en France). Bientôt, nous serons au Royaume-Uni. Nos bureaux à l’étranger sont indépendants, mais nous sommes unis par les mêmes missions, valeurs et stratégies. C’est ainsi que nous aurons une croissance à échelle humaine.
Exploiter les données de votre organisation avec les bases de données vectorielles

Chez Osedea, nous sommes constamment à l'avant-garde des technologies émergentes, et nous avons une perspective unique sur les tendances en matière d'adoption technologique parmi notre base de clients diversifiée. Ces derniers mois, l'IA a fait son entrée dans les médias grand public grâce à ChatGPT. Depuis lors, les outils et le soutien au développement de l'IA ont explosé. Il y a quelques semaines à peine, le Dr Andrew Ng, un leader mondialement reconnu en IA, a prononcé un discours sur les opportunités offertes par l'IA, mettant en évidence l'importance de l'intégration de l'IA dans le flux de travail de votre organisation.
BEARING.ai, la première entreprise à exploiter la puissance de l'IA générative dans l'industrie maritime, est un excellent exemple de la rapidité avec laquelle l'adoption de l'IA peut apporter d'énormes avantages. En utilisant leurs données pour surveiller, prévoir, simuler et optimiser, les clients de BEARING.ai ont réalisé des améliorations substantielles des performances des navires tout en réduisant simultanément les coûts de carburant et les émissions de carbone, contribuant ainsi à un environnement plus vert. Des opportunités similaires ne sont pas des rêves lointains ; elles sont à portée de main. L'IA est prête à être adoptée, et la clé pour en exploiter tout son potentiel réside dans l'utilisation des données de votre organisation.
Les avantages de la centralisation des données
Pour de nombreuses entreprises établies, les données s'accumulent depuis des années dans divers départements et systèmes. Les PDF, les images, les présentations, les e-mails, l'audio, la vidéo et les analyses regorgent d'informations (et sont des actifs importants lorsqu'ils sont exploités correctement). La première étape vers l'adoption de l'IA au sein de votre organisation consiste à centraliser vos données. La centralisation (la consolidation de diverses sources/emplacements dans un seul référentiel ou système) en mettant en place une plateforme de gestion unifiée des données ou en intégrant des systèmes existants grâce à des solutions middleware offre de nombreux avantages :
Base de connaissances alimentée par l'IA : Une fois centralisées, les données peuvent être organisées et indexées de manière efficace grâce à l'aide de modèles d'incorporation. Ces modèles sont formés pour extraire les informations les plus significatives de vos données non structurées. En indexant vos données de cette manière, les grands modèles de langage tels que GPT-4 peuvent étendre leur contexte avec le contexte commercial de votre organisation pour évoluer en un assistant complet et omniscient. Cette approche innovante est connue sous le nom de génération augmentée de récupération (RAG) avec des bases de données vectorielles, un concept que nous aborderons bientôt.
Formation de modèles prédictifs : Le pool de données consolidé devient une ressource précieuse pour la formation de modèles d'IA. Les analyses prédictives, les prévisions et l'analyse des tendances deviennent des objectifs réalisables lorsque vous capitalisez sur les données historiques de votre organisation.
Avantages en matière de sécurité : La centralisation des données offre une infrastructure de sécurité plus robuste pour protéger les informations sensibles. Elle permet un meilleur contrôle d'accès et une meilleure auditabilité, réduisant ainsi le risque de violations de données.
Sauvegardes plus faciles : Les données centralisées sont plus faciles à sauvegarder que les données provenant de sources disparates. Cela simplifie les mesures de protection des données, garantissant que les informations critiques sont préservées en toute sécurité et récupérables en cas de perte de données.
Redondance : La mise en place de la redondance, telle que la mise en miroir ou la réplication des données, devient plus réalisable avec des données centralisées. La redondance améliore la disponibilité des données et la tolérance aux pannes, réduisant les temps d'arrêt et assurant la continuité des activités.
Création d'une base de connaissances alimentée par l'IA
Comme mentionné précédemment, les systèmes de génération augmentée de récupération (RAG) ont pris de l'importance en tant que solution précieuse pour interroger les données d'une organisation à l'aide de grands modèles de langage (LLM). Les systèmes RAG permettent d'interroger les données en langage naturel. Fondamentalement, cela vous permet de "parler" à vos données de la même manière que vous parlez à ChatGPT. L'accessibilité des LLM au cours des derniers mois a rendu cette approche beaucoup plus faisable, c'est pourquoi cette approche de l'exploration des données gagne rapidement du terrain. Cependant, le succès de ces systèmes dépend non seulement des LLM et de l'ingénierie des invites, mais aussi de la vectorisation et de l'indexation correctes des données. C'est là que les bases de données vectorielles et les incorporations jouent un rôle crucial.
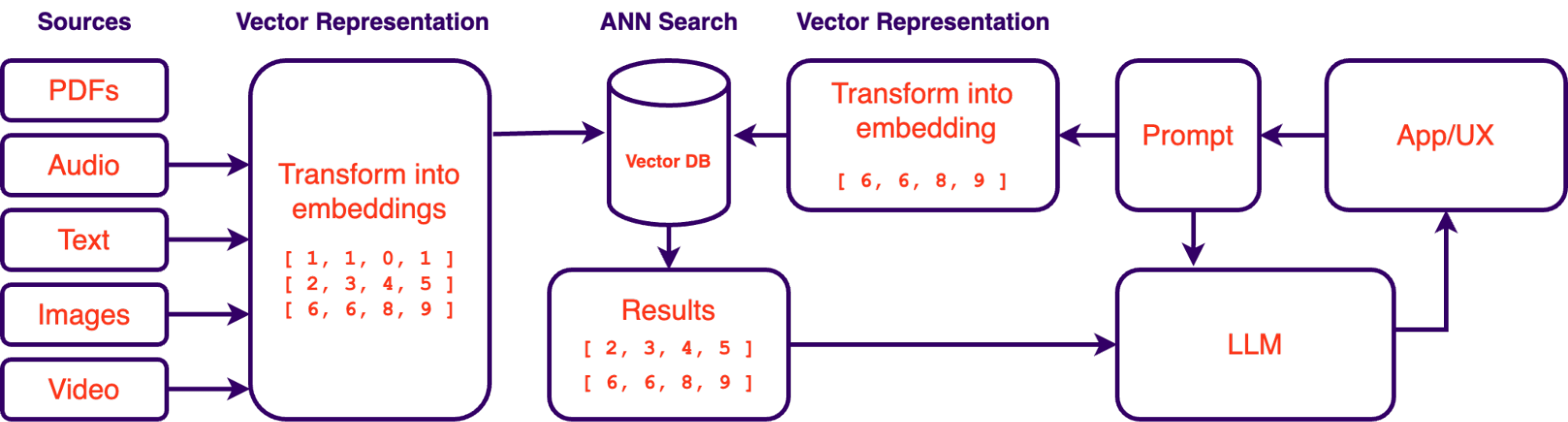
Qu'est-ce que les incorporations vectorielles ?
Dans le contexte de l'IA et de l'apprentissage automatique, les incorporations vectorielles sont une représentation numérique de la sémantique d'une entité. Ces représentations capturent les caractéristiques essentielles et les relations au sein des données, facilitant ainsi le traitement et la compréhension par les algorithmes d'IA. Les incorporations sont essentielles pour des tâches telles que le traitement du langage naturel, les systèmes de recommandation et la reconnaissance d'images. Grâce aux incorporations, nous pouvons rapidement trouver du contenu similaire en fonction de la similitude. De plus, les incorporations ne se limitent pas aux seuls textes, il est possible de créer des vecteurs à partir d'images, d'audio, de vidéos ou de tout type de données en utilisant des modèles d'encodeur formés pour extraire leurs informations significatives. Certains modèles, comme le modèle d'incorporation de texte d'OpenAI-ada-002, sont même agnostiques à la langue, ce qui signifie qu'ils peuvent comprendre la similitude dans diverses langues de manière native.
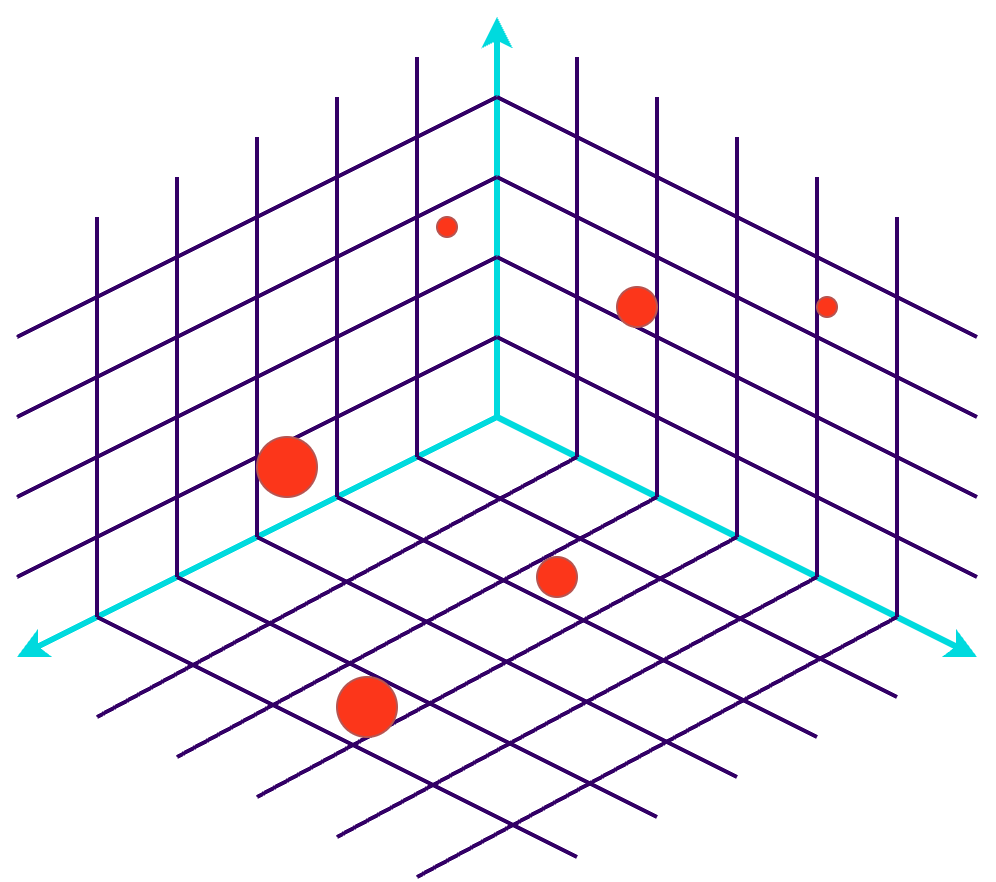
Qu'est-ce qu'une base de données vectorielle ?
Une base de données vectorielle est une base de données spécialisée conçue pour stocker et récupérer efficacement des incorporations vectorielles en haute dimension, ce qui les rend idéales pour les applications d'IA et d'apprentissage automatique. Elles utilisent des algorithmes de recherche d'approximation du plus proche voisin (ANN) pour mesurer la distance entre les incorporations, ce qui donne une liste classée de vecteurs voisins.
À titre d'exemple, Spotify utilise des bases de données vectorielles depuis un certain temps pour comparer les goûts musicaux des utilisateurs. Ils détaillent également comment ils ont utilisé des incorporations pour interroger leurs épisodes de podcast dans leur article de blog : Présentation de la recherche de langage naturel pour les épisodes de podcast. Ils sont même allés jusqu'à créer leur propre bibliothèque ANN !
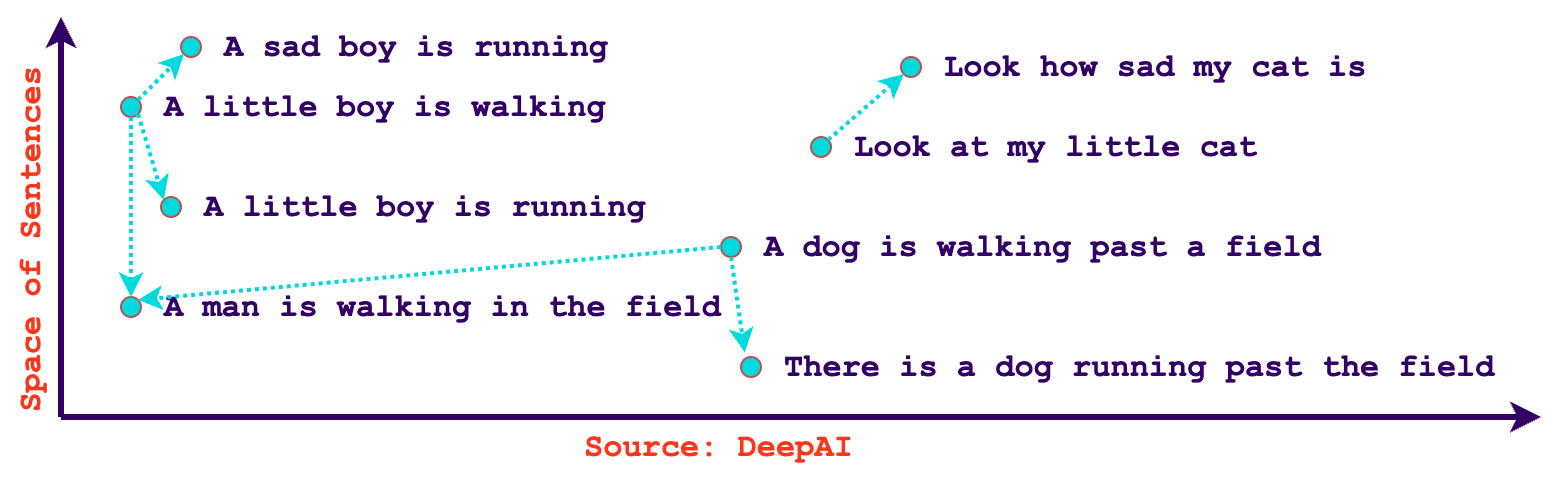
Des cas d'utilisation pour les bases de données vectorielles
Les bases de données vectorielles conviennent parfaitement à un large éventail de cas d'utilisation impliquant la recherche de similitudes, les systèmes de recommandation et l'analyse des données dans des domaines tels que l'apprentissage automatique, le traitement du langage naturel, la vision par ordinateur, et bien d'autres. Voici quelques cas d'utilisation courants pour les bases de données vectorielles :
Systèmes de recommandation : Les bases de données vectorielles sont souvent utilisées dans les systèmes de recommandation pour trouver des articles ou du contenu similaire à ce avec quoi un utilisateur a interagi dans le passé. Cela peut s'appliquer au commerce électronique, à la recommandation de contenu, et aux plateformes de musique ou de streaming vidéo.
Recherche basée sur le contenu : Dans les plates-formes de contenu multimédia, les bases de données vectorielles permettent la recherche basée sur le contenu pour les images, l'audio et les fichiers vidéo. Les utilisateurs peuvent rechercher du contenu avec des caractéristiques visuelles ou auditives similaires.
Détection d'anomalies : La détection d'anomalies dans les données de haute dimension, telles que les journaux de trafic réseau, les données de capteurs ou les transactions financières, peut être effectuée à l'aide de bases de données vectorielles. Les points de données inhabituels peuvent être identifiés en les comparant à un ensemble de vecteurs normaux.
Filtrage collaboratif : Les algorithmes de filtrage collaboratif peuvent utiliser des bases de données vectorielles pour trouver des utilisateurs ayant des préférences similaires et recommander des éléments en fonction du comportement d'utilisateurs similaires.
Mémoire à long terme : Les bases de données vectorielles peuvent être utilisées pour stocker les générations de réponses passées d'un LLM. Ces incorporations peuvent être rappelées pour améliorer davantage le contexte d'un modèle de langage avec son contexte passé.
Regroupement : Dans les bases de données vectorielles, le regroupement peut être appliqué pour organiser les données en groupes distincts, facilitant ainsi l'identification de motifs et de similitudes au sein de l'ensemble de données.
Mesure de la diversité : Dans les bases de données vectorielles, la mesure de la diversité peut être appliquée pour évaluer l'étendue et l'inclusivité des recommandations, garantissant une sélection équilibrée d'articles ou de contenu pour répondre à un large éventail de préférences ou de sujets d'utilisateurs.
Les écueils des modèles d'incorporation et des bases de données vectorielles
Bien que les incorporations soient puissantes, elles ne sont pas sans leurs défis. Il est important de connaître les écueils potentiels, tels que les biais dans les données d'entraînement. Par exemple, OpenAI explique dans sa documentation comment un modèle peut associer de manière plus marquée des noms européens américains à un sentiment positif par rapport aux noms africains américains. De plus, les modèles d'incorporation ont des dates de coupure sur leurs données d'entraînement, ce qui signifie que certaines données peuvent varier sémantiquement au fil du temps (par exemple, la popularité d'une célébrité). Le choix des bonnes techniques d'incorporation et des paramètres est essentiel pour obtenir des résultats optimaux, et des techniques appropriées de prétraitement des données doivent être appliquées pour exploiter correctement les incorporations.
Les bases de données vectorielles ne sont que la moitié de la solution
Bien que les bases de données vectorielles et les incorporations soient des composants essentiels de l'adoption de l'IA, il est essentiel de reconnaître qu'ils font partie d'un écosystème plus vaste. La création d'une infrastructure d'IA robuste implique de s'attaquer à d'autres aspects clés tels que le prétraitement des données, la sélection de modèles, l'ingénierie des invites et les stratégies de déploiement. Les bases de données vectorielles sont une pièce puissante du puzzle, mais elles ne sont pas la solution complète.
L'un des problèmes récurrents avec les LLM et l'IA en général est le compromis en termes de précision. Pendant des siècles, les ordinateurs ont été binaires et déterministes. Bien que les bases de données vectorielles puissent représenter une avancée monumentale dans l'exploration des connaissances, elles doivent encore être combinées avec des architectures structurées traditionnelles pour offrir une expérience de recherche ultime. Certaines plateformes, telles qu'Azure Cognitive Search et Elastic Search, travaillent activement à l'amélioration et à l'ajustement des recherches hybrides en utilisant la fusion des classements réciproques (RRF) pour mélanger les classements obtenus. Elastic s'attaque également à d'autres problèmes liés aux bases de données vectorielles, tels que la confidentialité des données et le contrôle d'accès basé sur les rôles (RBAC). Du côté de l'ingénierie des invites, divers cadres tels que guidance ai, Langchain et LMQL sont en cours de développement pour fournir une manière robuste de transformer les données des LLM en réponses structurées significatives. Inutile de dire que nous vivons des moments passionnants, et les architectures RAG émergentes s'améliorent chaque jour.
Chez Osedea, nous reconnaissons le potentiel des bases de données vectorielles, des incorporations et de l'IA pour provoquer des changements transformateurs au sein des organisations. Nos services de développement complets sont conçus pour donner à votre organisation les moyens d'exploiter ses données et de réaliser pleinement le potentiel de l'IA. Que ce soit la centralisation des données, la mise en place de bases de données vectorielles ou la navigation dans les complexités de l'adoption de l'IA, Osedea est là pour être votre partenaire de confiance sur la voie du succès axé sur les données. Soyez assuré que nous restons à l'avant-garde des technologies émergentes et que nous nous engageons à suivre les dernières avancées dans le domaine.
Comment élever l'engagement dans le contexte de travail hybride?
Au mois d'août, Zoom (célèbre pour nous avoir aidés à rester connectés pendant la pandémie) a ironiquement rappelé ses employés au bureau. Vous avez probablement remarqué cette tendance des entreprises à ramener leurs équipes en présentiel. Dans mon réseau, on impose un retour en présentiel 2 à 3 fois par semaine.
Je suis d’accord avec le besoin de créer un environnement de travail engageant où la collaboration règne. Par contre, j’ai de la difficulté avec la décision d'imposer un nombre fixe de jours par semaine. Je crains que les travailleurs qui prospèrent dans des environnements de travail à distance deviennent moins engagés, voire partent tout simplement. On peut se poser la question : le problème d'un engagement plus faible sera-t-il résolu magiquement en ayant les gens de retour au même endroit physique? J'en doute. Après tout, le désengagement et le manque de cohésion dans les équipes existaient avant la pandémie. Je nous encourage à prendre une pause collective pour réfléchir aux solutions qui font du sens.
En parlant à l’équipe chez Osedea, il y a un consensus : l’équipe souhaite que leurs collègues soient plus présents en personne... D’un autre côté, tout le monde apprécie unanimement l'extrême flexibilité que nous offrons.
Dans cet article, je partage mes réflexions et nos apprentissages sur l'évolution des dynamiques de travail, dans l'espoir que cela puisse vous aider dans vos propres réflexions.
Créez des moments mémorables ensemble
Gregg Popoich, l'entraîneur légendaire des San Antonio Spurs, emmène son équipe après chaque match à une excellente expérience culinaire. Les joueurs de la NBA (dont beaucoup sont millionnaires) peuvent se payer toute sorte d’expérience. Mais, comme l'a souligné l'ancien garde des Spurs, Danny Green, dans un article de ESPN en 2020 sur la mentalité de Popovich, « les repas d’équipe nous aident à mieux comprendre chaque personne individuellement, ce qui nous rapproche les uns des autres... et, sur le terrain, à mieux nous comprendre mutuellement. »
En effet, rien ne favorise la cohésion d'équipe comme vivre des expériences mémorables et uniques ensemble. C'était quelque chose que nous faisions très bien au début d'Osedea, lorsque notre équipe était plus petite. Chaque année, nous organisions un voyage tout inclus de cinq jours avec notre équipe. Au menu : formations et cohésion d’équipe. Vous pouvez en savoir plus sur notre voyage à Lisbonne en 2018 ici.
À mesure que nous avons grandi, la logistique de l'organisation de voyages d'équipe réguliers est devenue plus complexe. Il y aussi eu la pandémie. Cette année, nous avons canalisé l'état d'esprit de nos voyages d'équipe et l'avons appliqué au lancement d'OsedeaFest : deux journées pleines d'ateliers inspirants, de délicieux repas et de la découverte de notre ville. Le résultat? Une augmentation de l'engagement et de la connexion de l'équipe, selon nos résultats dans Officevibe et les commentaires de notre équipe.
Organisez vos journées en personne autour de rituels
Il y a certaines activités qui ont plus de sens en personne, tandis que d'autres non. Par exemple, l'été dernier, nous avons repris les entretiens en personne. Cela nous donne l'occasion de créer des liens et de rendre l'expérience du candidat plus mémorable. De même, les démos client sont une excellente occasion de développer des liens et d'offrir une expérience collaborative positive. Chaque fois que nous organisons certains types de rituels, nous nous demandons : est-ce mieux en personne, à distance, ou les deux fonctionnent-ils bien? Nous organisons désormais nos journées en personne autour de cela, plutôt que d'attribuer un nombre arbitraire de jours où les gens doivent être physiquement présents.
Offrez de la flexibilité. Obtenez de la flexibilité en retour.
Notre équipe apprécie la flexibilité que nous offrons. Certains membres de l'équipe, comme moi (quel plaisir de rester quatre minutes à pied du bureau!), viennent au bureau la plupart des jours. D'autres sont réguliers, mais sans jours fixes. D'autres encore sont rarement présents en personne. Cependant, lorsque nous avons une journée d'entretiens, nous n'avons jamais à supplier notre équipe de se présenter ou à négocier leur présence. Nous savons qu'ils respectent le processus, même s'ils sont du type à préférer le travail à distance.
Communiquez différemment pour engager efficacement vos équipes
Un commentaire que j'entends souvent de la part d'autres dirigeants d'entreprise est qu'ils craignent que, s'ils passent entièrement en télétravail, leur équipe sera désengagée de leur entreprise. Si vous pensez qu'être présent en personne pour la communication vous empêchera d'avoir une main-d'œuvre désengagée, je vous invite à réfléchir à nouveau. Nous devons nous remettre en question en tant que leaders, penser différemment et trouver des moyens innovants de communiquer et d'engager l'équipe.
Voici quelques-unes des choses que nous avons faites pour améliorer la communication et l'engagement :
- Impliquez votre équipe en explorant de nouvelles façons de communiquer. Nous avions une infolettre interne qui a duré trois ans avant de commencer à perdre de son impact. Nous avons changé de cap vers un média très engageant : un balado interne. Une fois par semaine, nous diffusons un épisode mettant en vedette différents membres de l'équipe. C'est un excellent moyen de créer une connexion personnelle avec les l’équipe, qui peut l’écouter à sa guise.
- Revoyez les rituels de communication existants. Nous avions organisé notre mise à jour trimestrielle de la même manière (en style de conférence vidéo traditionnelle avec une présentation visuelle) depuis notre création. Pour rendre la présentation de ce contenu important plus dynamique, nous avons changé les choses cet automne avec un format de talk-show virtuel.
Mot de la fin
Selon Indeed, le travail hybride est là pour rester, avec plus de 42 % des emplois affichés dans divers secteurs, y compris des offres de travail hybride. Cependant, le travail hybride peut être bien plus inspirant et gratifiant pour votre équipe qu'une règle monotone imposant un nombre fixe de jours par semaine au bureau. La flexibilité et une approche adaptée à votre équipe peuvent être des différenciateurs plus forts pour attirer des talents et offrir des expériences professionnelles enrichissantes. Alors, avant de sauter dans le train du retour au bureau, je vous encourage à vous poser la question : « pouvons-nous faire mieux? ».
Osedea crée un programme équitable et inclusif pour les parents
Les employés méritent plus qu’une assurance dentaire rudimentaire et quelques cours de yoga pour exceller personnellement et professionnellement. C’est pourquoi, soucieux de prendre soin des membres de notre équipe, nous nous faisons un devoir de les aider à réaliser leurs rêves. Et ce ne sont pas là des paroles en l’air : nous investissons dans des avantages sociaux inclusifs et équitables qui ont des retombées concrètes dans leur vie.
Un exemple? Nous les soutenons lorsqu’ils veulent fonder une famille, quel que soit le chemin emprunté.
Voici quelques raisons pour lesquelles ce projet nous tient à cœur :
- Le Québec – berceau de notre agence – est en avance sur la plupart des provinces canadiennes en matière de prestations parentales grâce au Régime québécois d’assurance parentale (RQAP). Mais il reste que le RQAP ne couvre pas 100 % du salaire du parent pendant son absence du travail.
- Le programme de procréation médicalement assistée lancé en 2021 au Québec comporte des zones grises, et dans bien des cas, il n’est pas adapté à la réalité des personnes. Ce programme manque d’inclusivité, notamment pour les mères porteuses et les couples homosexuels.
- Pour des raisons financières, il arrive souvent qu’un nouveau parent hésite à prendre un long congé parental; il perd alors de précieux moments avec son enfant dès ses premiers jours.
Un programme plus équitable pour les parents
Pour donner à nos employés la chance de fonder une famille sans avoir à faire de sacrifices, quelle que soit leur identité de genre ou leur orientation sexuelle, nous avons créé un tout nouveau programme d’avantages sociaux nommé Un plus pour la famille.
Ce nouveau programme est conçu pour soutenir les membres d’Osedea dans leur cheminement parental, toujours sous le signe de l’inclusion (sans égard au sexe ou au diagnostic). Il vient combler les lacunes des programmes gouvernementaux, favoriser l’égalité et offrir du choix, de la flexibilité et du soutien sur le chemin de la parentalité, qui diffère d’une personne à l’autre.
« Décider de fonder une famille, c’est un gros projet, et un projet emballant, affirme Martin Coulombe, fondateur d’Osedea. Nous croyons que toute personne peut prendre soin d’un enfant, quelle que soit son identité de genre ou son orientation sexuelle. C’est pourquoi nous offrons à tous les membres de notre entreprise une aide égale pour fonder une famille, en prendre soin et tisser de précieux liens avec bébé. »
Un plus pour la famille est l’un des premiers programmes au Québec à financer les traitements de fertilité, l’adoption et les congés parentaux pour aider les employés à fonder une famille à leur façon. Il comprend divers avantages qui offrent soutien et flexibilité tout au long du cheminement parental.
Voici les détails de notre nouveau programme :
- 80 % des coûts des traitements de fertilité, jusqu’à concurrence de 20 000 $ CA, y compris :
- Cycles supplémentaires de traitement de stimulation ovarienne.
- Cycles supplémentaires de traitement de fécondation in vitro (FIV)
- Cycles supplémentaires de traitement d’insémination intra-utérine
- Cycles de préservation de la fertilité pour les personnes de tous genres, dont cinq ans d’entreposage
- Frais liés au recours à une mère porteuse
- 80 % des frais d’adoption locale ou internationale, y compris les honoraires d’avocat, jusqu’à concurrence de 20 000 $ CA
- En plus des prestations gouvernementales : 12 semaines de congé payé par l’employeur à 100 % du salaire pour tout membre de l’équipe parentale, y compris les parents biologiques, les parents adoptifs, les conjoints de fait et les tuteurs légaux
Notre objectif est de placer l’employé ou l’employée au cœur du processus décisionnel, de lancer la discussion sur les programmes de prestations parentales qui incluent la communauté LGBTQIA+ et d’inciter d’autres entreprises à emboîter le pas, pour ainsi créer une société plus équitable pour les parents.
Nous cherchons constamment à élargir nos horizons et à partager nos acquis. Rien de mieux pour repousser les limites et nous surpasser!